组件自动伸缩
组件的负载会不停的变化, 时高时低, 很难为其配置合适的资源; Rainbond 引入自动伸缩, 可以很好地解决这个问题. 组件自动伸缩会一直观察用户设置的指标, 一旦该指标超过或低于期望阈值, 就会自动地对组件进行伸缩.
本文会根据以下三方面来介绍组件的自动伸缩功能:
- 组件自动伸缩的原理.
- 组件自动伸缩的使用方法.
- 一个关于组件自动伸缩的演示例子.
组件自动伸缩的原理
组件的自动伸缩有两种, 分别是 水平自动伸缩 和 垂直自动伸缩. 水平伸缩, 增加或减少组件的副本数; 而自动水平伸缩则是, 根据组件的 CPU 使用率, 内存或其他自定义指标, 自动的执行组件的水平伸缩.
垂直伸缩, 为组件分配更多或更少的 CPU 和内存; 而自动垂直伸缩则是, 根据组件的 CPU 使用率, 内存或其他自定义指标, 自动的执行组件的垂直伸缩.
目前(5.1.9), Rainbond 只支持组件的水平自动伸缩, 所以本文不会涉及太多的 垂直自动伸缩.
组件水平自动伸缩
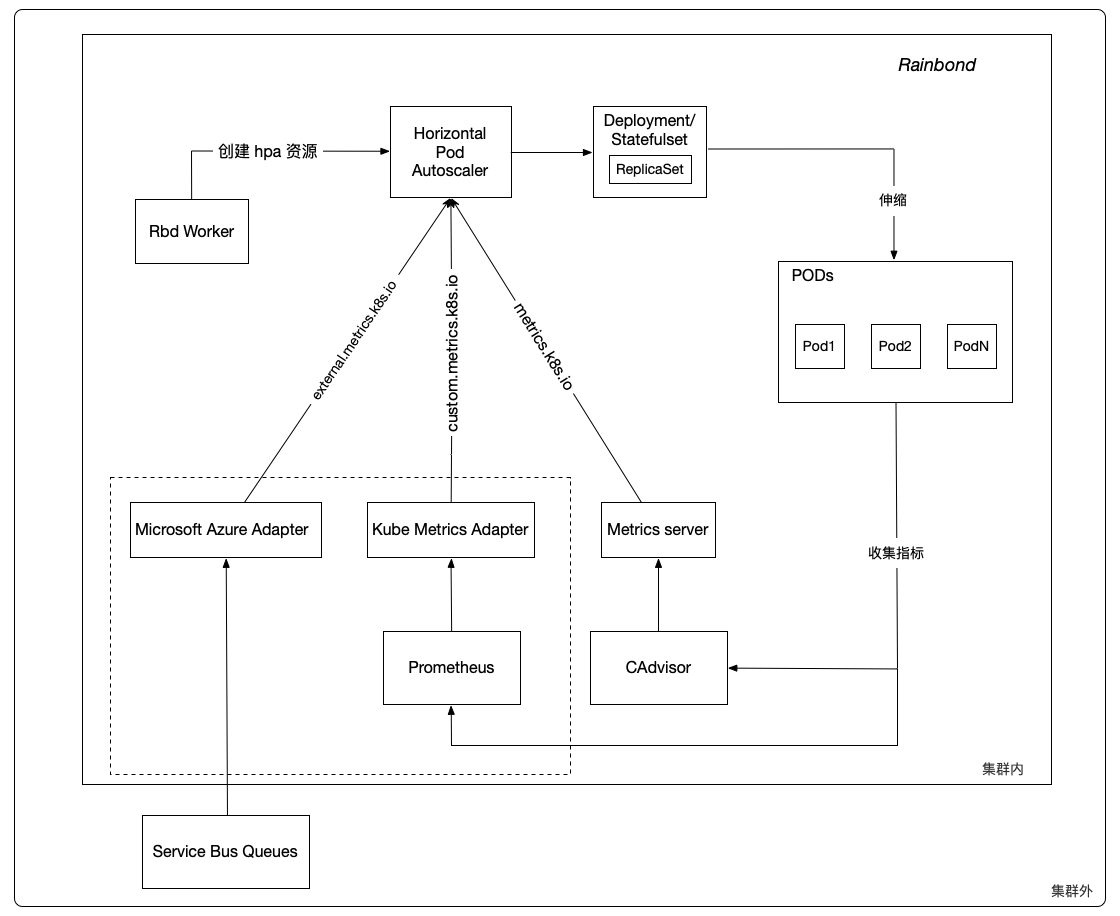
Horizontal Pod Autoscaler 由两部分组成, HPA 资源 和 HPA 控制器. HPA 资源 定义了组件的行为, 包括指标, 期望值, 和最大最小副本数等. HPA 控制器, 周期性地检查检查组件所设置的指标; 其周期由 controller manager 的参数 --horizontal-pod-autoscaler-sync-period 控制, 默认是 15 秒。
Rbd Worker 负责将你在云帮控制台为组件设置的指标, 期望值, 和最大最小副本数等参数, 转化成 kubernetes 集群中的 HPA 资源. 供 HPA 控制器使用。
在每个周期中, HPA 控制器通过 mertrics API 查询用户为每个组件设置的指标; 当指标超过或低于期望阈值时, HPA 控制器会调整 Deployment/Statefulset 中的副本数, 最后由 Deployment/Statefulset 完成组件实例数的增加或减少。
HPA 控制器一般从 metrics.k8s.io, custom.metrics.k8s.io 和 external.metrics.k8s.io 三个聚合 API 观察指标。
metrics.k8s.io 这个 API 由 metrics-server 提供, 对应的是资源指标(resource metrics), 即 CPU 使用率, CPU 使用量 和 内存使用率, 内存使用量. 也是 Rainbond 目前支持的指标��类型。
custom.metrics.k8s.io 对应的是 自定义指标, external.metrics.k8s.io 对应的是 外部指标. 比如: 每秒请求数(requests-per-secon), 每秒接收的包数(packets-per-second).
由 Kube Metrics Adapter, Prometheus Adapter
或者是自己实现的遵循了 Kubernetes metrics API 定义 的第三方服务提供. 自定义指标和外部指标大体上是相同的.
自定义指标不支持使用率, 只能是值, 或者说 使用量, 是组件的每个实例的平均值.
目前 5.1.9, Rainbond 只支持 资源指标, 即与 CPU 和内存相关的指标. 虚线框里自定义指标和外部指标, 会在未来的版本中实现.
水平自动伸缩的算法
从最基本的角度来看,Horizontal Pod Autoscaler 根据 指标目标值 和 指标实际值 的比来计算期望的实例数:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
举个例子, 如果指标实际值是 200m, 期望值时 100m, 那么实例数将会翻倍, 因为 200.0 / 100.0 == 2.0; 如果实际值降低到了 50m, 那么
实例数不变, 因为 50.0 / 100.0 == 0.5(比率接近 1.0, HPA 控制器将会跳过缩放).
组件自动伸缩的使用
组件的自动伸缩位于组件页面的伸缩选项中, 在手动伸缩下方.
如 组件水平自动伸缩 所提及, 你可以在自动伸缩页面设置自动伸缩的最大副本数, 最小副本数 和 指标.
最大实例数
当指标的实际值超过其期望值时, 组件的实例数会不断地增加, 尽可能使指标的实际值低于期望值. 当实例数等于最大实例数后, 指标的实际值
仍然高于期望值, 那么实例数定格在了最大实例数, 不会继续增长.
最小实例数
当指标的实际值低过其期望值时, 组件的实例数会不断地减少, 尽可能使指标的实际值接近期望值. 当实例数等于最小实例数后, 指标的实际值
仍然没有接近期望值, 那么实例数定格在了最小实例数, 不会继续减少.
指标
目前, Rainbond 仅支持资源指标(resource metrics), 即 CPU 使用率, CPU 使用量, 内存使用率 和 内存使用量.
CPU 使用量的单位是 m, 1m 等于千分之一核. 内存使用量的单位是 Mi.
指标支持添加和删除, 遵循以下的规则:
- 关于 CPU 的指标只能有一个, 即
CPU 使用率,CPU 使用量两个指标不能共存. 内存也是如此. - 至少有一个指标, 即无法删除全部指标.
- 指标值必须是大于 0 的整数.
以上 3 类参数的修改, 无需更新或重启组件, 修改成功立刻生效.
一个演示例子
创建组件 hpa-example
为了演示组件的水平自动伸缩,我们将使用基于 php-apache 镜像的自定义 docker 镜像. Dockerfile 的内容如下:
FROM php:5-apache
ADD index.php /var/www/html/index.php
RUN chmod a+rx index.php
它定义了一个 index.php 页面,该页面执行一些非常消耗 CPU 计算:
<?php
$x = 0.0001;
for ($i = 0; $i <= 1000000; $i++) {
$x += sqrt($x);
}
echo "OK!";
?>
你可以根据上面的 Dockerfile 构建出镜像, 也可以使用我们准备好的镜像 abewang/hpa-example:latest. 我们用这个镜像, 创建一个内存上限为 128M, 端口为 80 的组件.
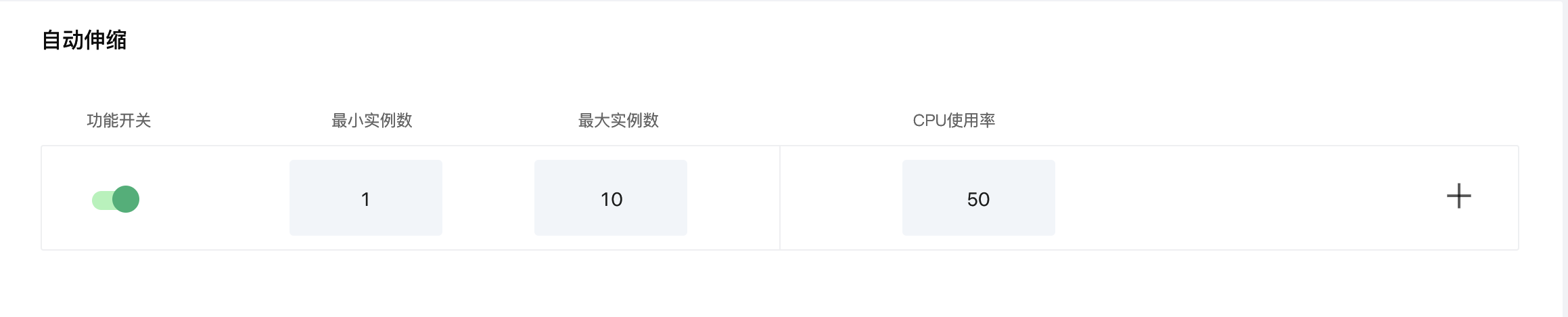
配置自动伸缩
我们设置最大实例数为 10, 最小实例数为 1, CPU 使用率为 50%. 粗略地说,HPA 将(通过部署)增加或减少副本数,以将所有 Pod 的平均 CPU 使用率 维持在 50%. 如下图所示:
我们使用命令行检查 hpa 目前的状态:
root@r6dxenial64:~# kubectl get hpa --all-namespaces
NAMESPACE NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
6b981574b23d4073a226cf95faf497e3 a737ffa9edca436fadb609d5b3dab1bd Deployment/5a8e8667d96e194be248f2856dcaedda-deployment 1%/40% 1 10 1 1h
增加负荷
现在, 我们打开一个 Linux 终端, 用一个无限循环向 php-apache 服务发送消息.
# 请将 http://80.grcaedda.eqfzk1ms.75b8a5.grapps.cn 换成你实际的域名
while true; do wget -q -O- http://80.grcaedda.eqfzk1ms.75b8a5.grapps.cn; done
一分钟后, 我们用一下命令查看 hpa 的状态:
root@r6dxenial64:~# kubectl get hpa --all-namespaces
NAMESPACE NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
6b981574b23d4073a226cf95faf497e3 a737ffa9edca436fadb609d5b3dab1bd Deployment/5a8e8667d96e194be248f2856dcaedda-deployment 270%/40% 1 10 1 1h
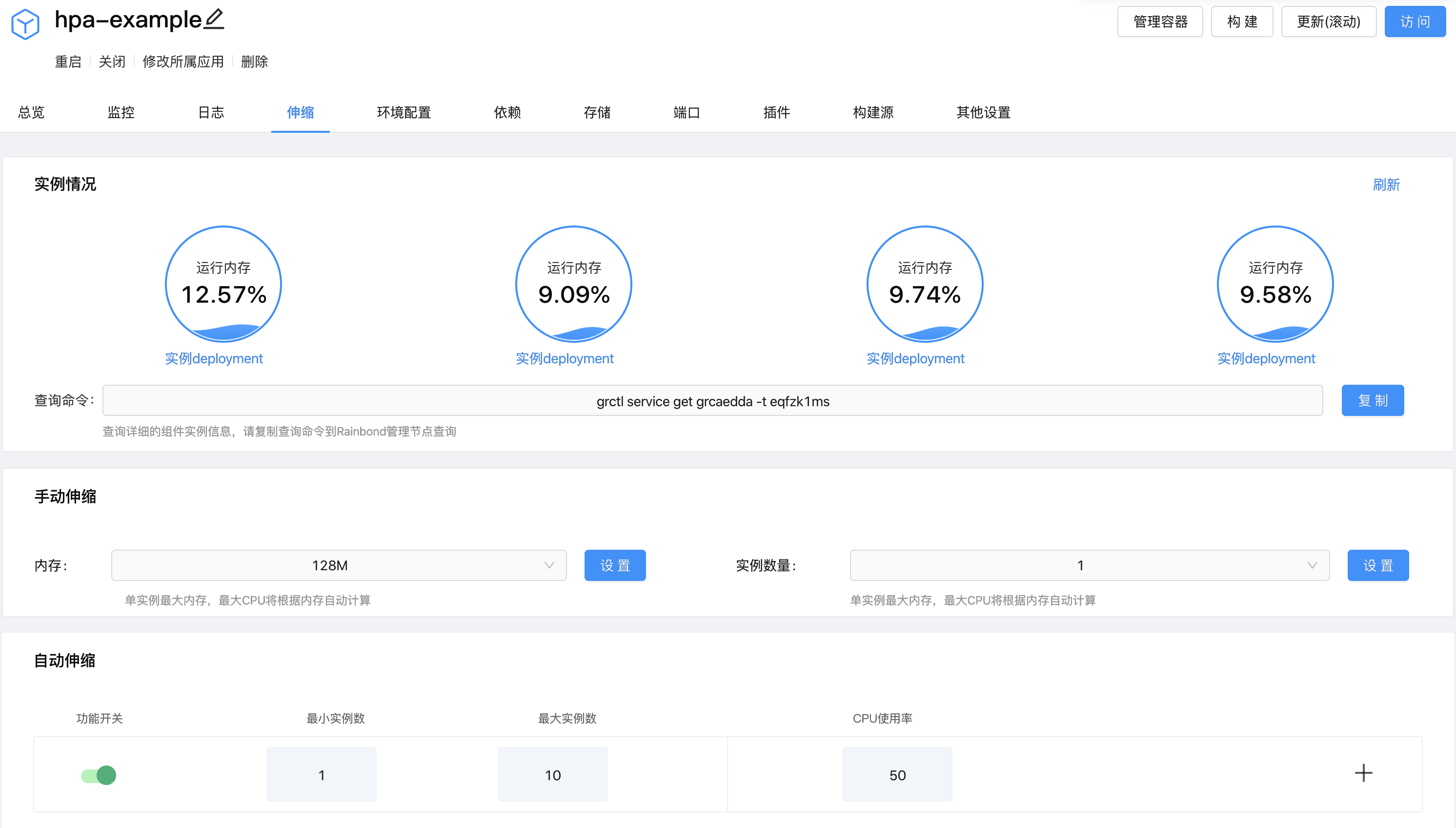
可以看出, CPU 的使用率已经上升到了 270%. 这导致实例数被增加到了 4 个. 如下图所示:
降低负荷
现在, 我们把上面再 Linux 终端中运行的无限循环给停掉, 来降低组件的负载. 然后, 我们来检查 hpa 的状态, 如下:
root@r6dxenial64:~# kubectl get hpa --all-namespaces
NAMESPACE NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
6b981574b23d4073a226cf95faf497e3 a737ffa9edca436fadb609d5b3dab1bd Deployment/5a8e8667d96e194be248f2856dcaedda-deployment 3%/50% 1 10 1 1h
CPU 使用率降低到了 0, 所以实例数伸缩到了 1.
水平伸缩记录
我们来观察组件的水平伸缩记录, 看看这个过程发生了什么. 如下图所示:

我们配置完相关参数后, 水平自动伸缩开始生效, 但此时指标尚未准备好, 所以我们看到有两条获取指标失败的记录. 我们在一个无限循环不断给组件发送消息后, 水平自动伸缩检查到 CPU 使用率超过了目标值, 开始讲实例数伸缩到了 4, 再到 6. 当我们停止发送消息后, 负载下去了, 水平自动伸缩检查到 CPU 使用率低于目标值, 直接将实例数伸缩到了 1。
Rainbond 记录组件的实例变化过程,让运维人员可以随时查看组件的实例变化。