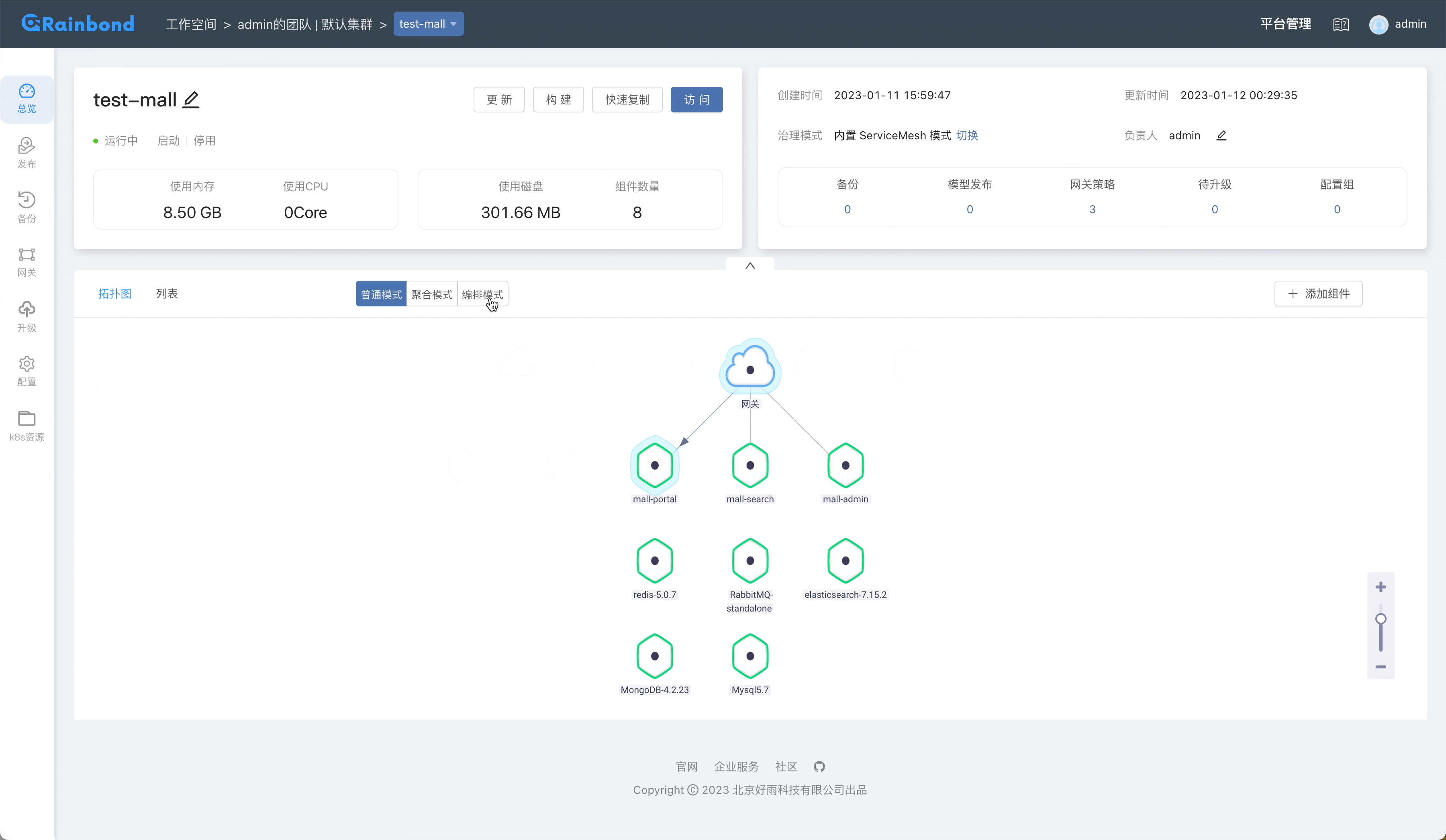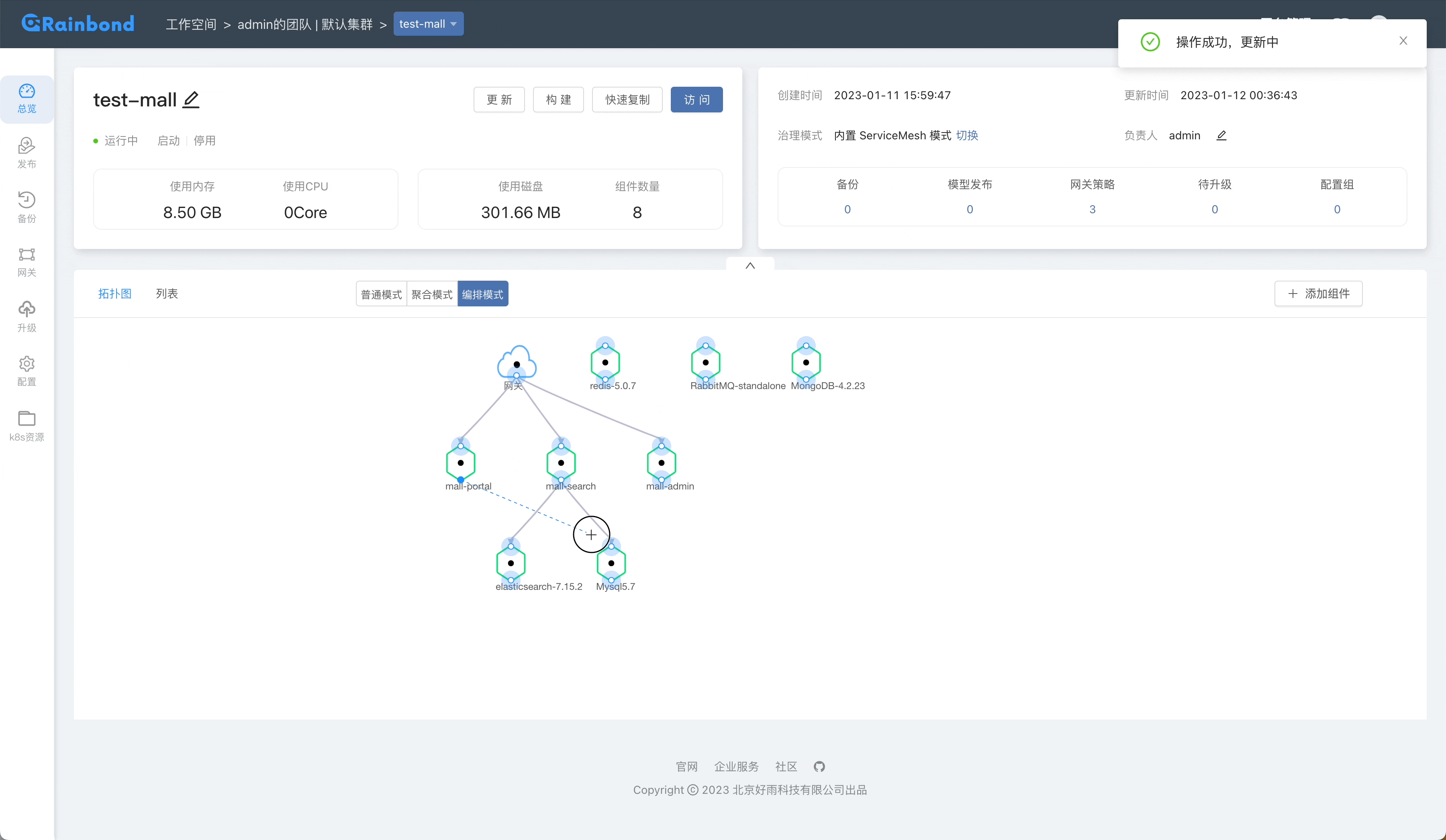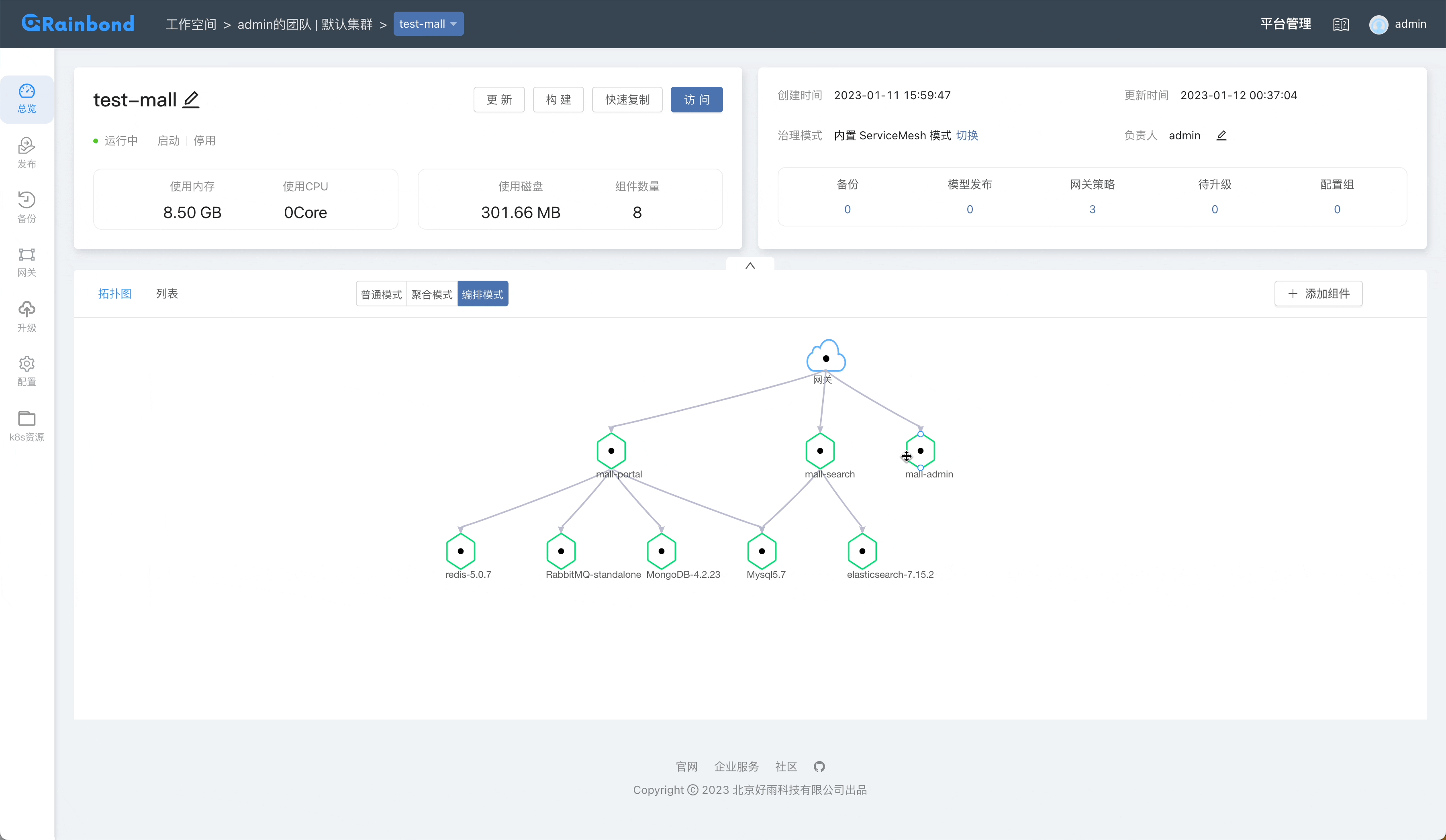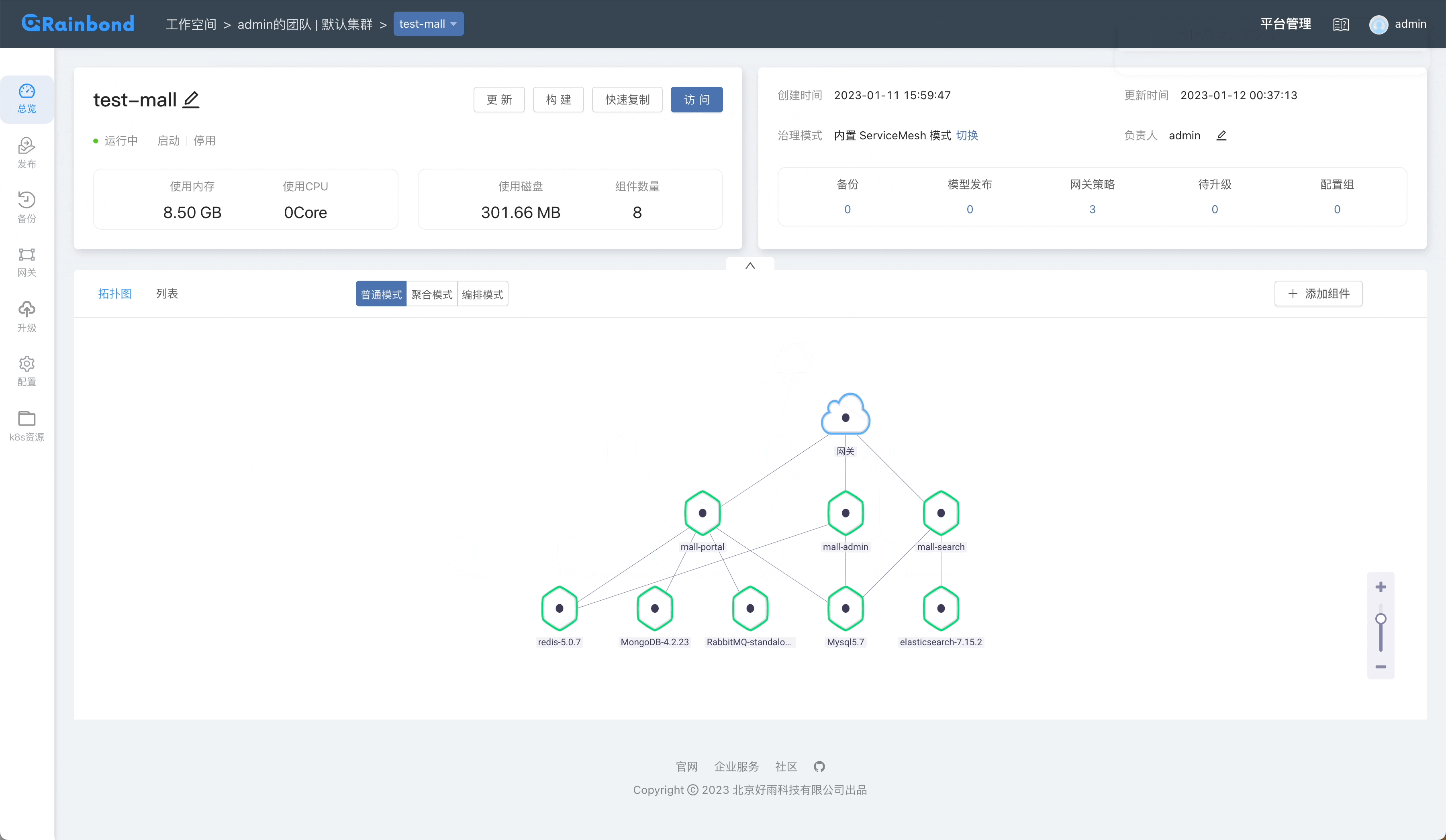
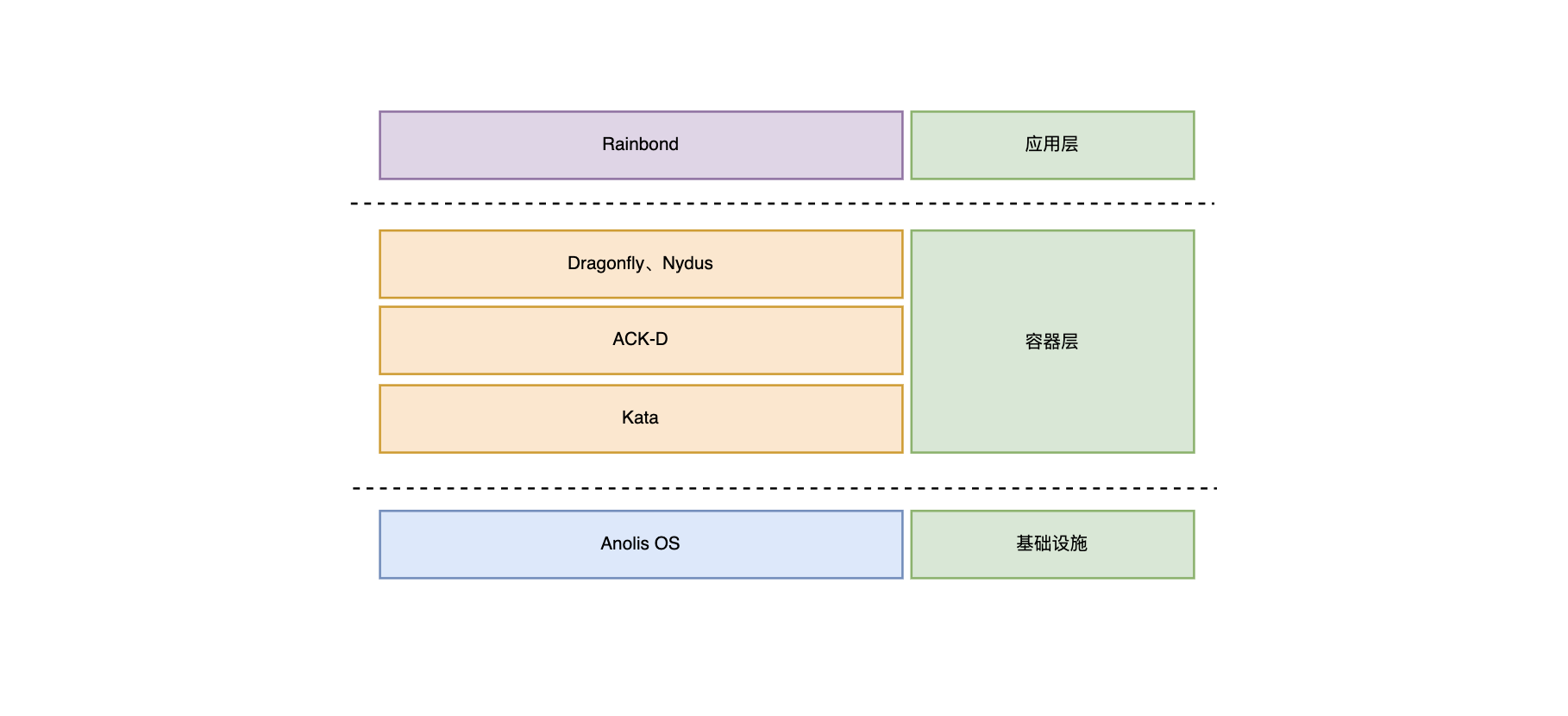
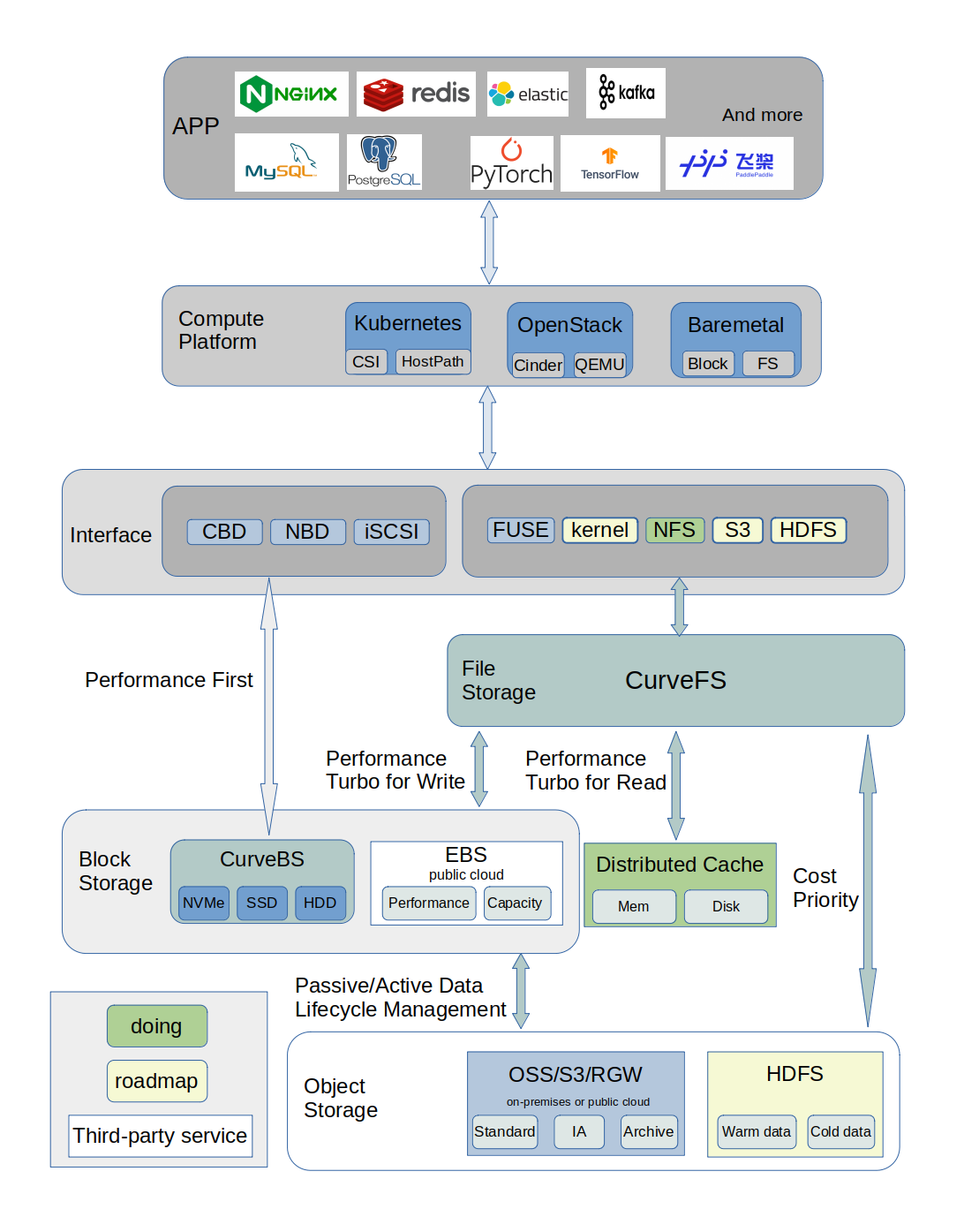
Curve 是网易主导自研的现代化存储系统, 目前支持文件存储(CurveFS)和块存储(CurveBS)。
CurveBS 的核心应用场景主要包括:
- 虚拟机/容器的性能型、混合型、容量型云盘或持久化卷,以及物理机的远程存储盘
- 高性能存算分离架构:基于RDMA+SPDK的高性能低时延架构,支撑MySQL、kafka等各类数据库、中间件的存算分离部署架构,提升实例交付效率和资源利用率
CurveFS 的核心应用场景主要包括:
- AI训练(含机器学习等)场景下的高性价比存储
- 大数据场景下的冷热数据自动化分层存储
- 公有云上高性价比的共享文件存储:可用于AI、大数据、文件共享等业务场景
- 混合云存储:热数据存储在本地IDC,冷数据存储在公有云
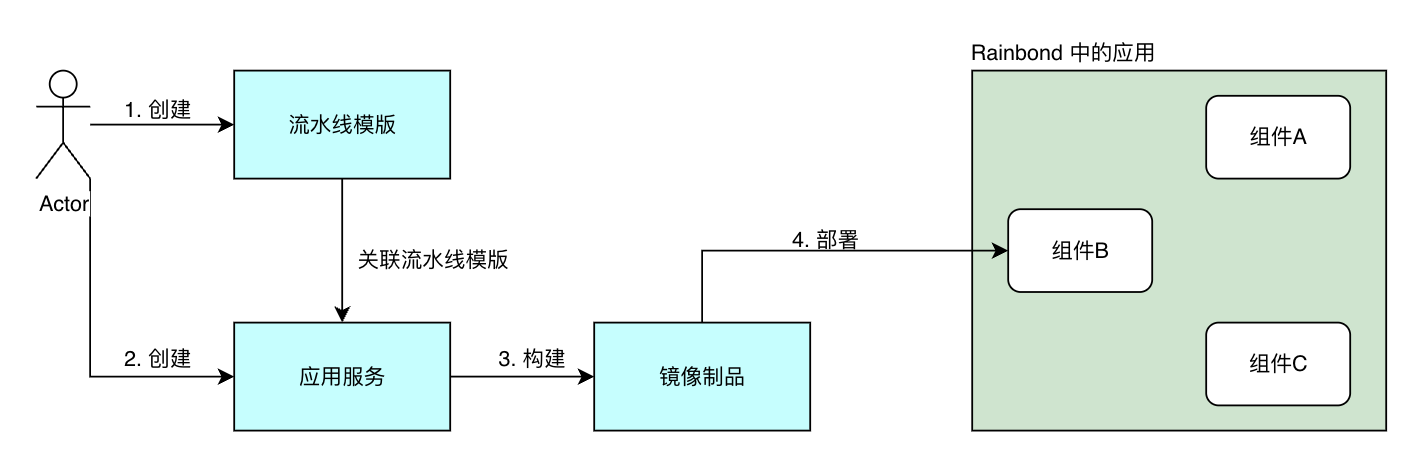
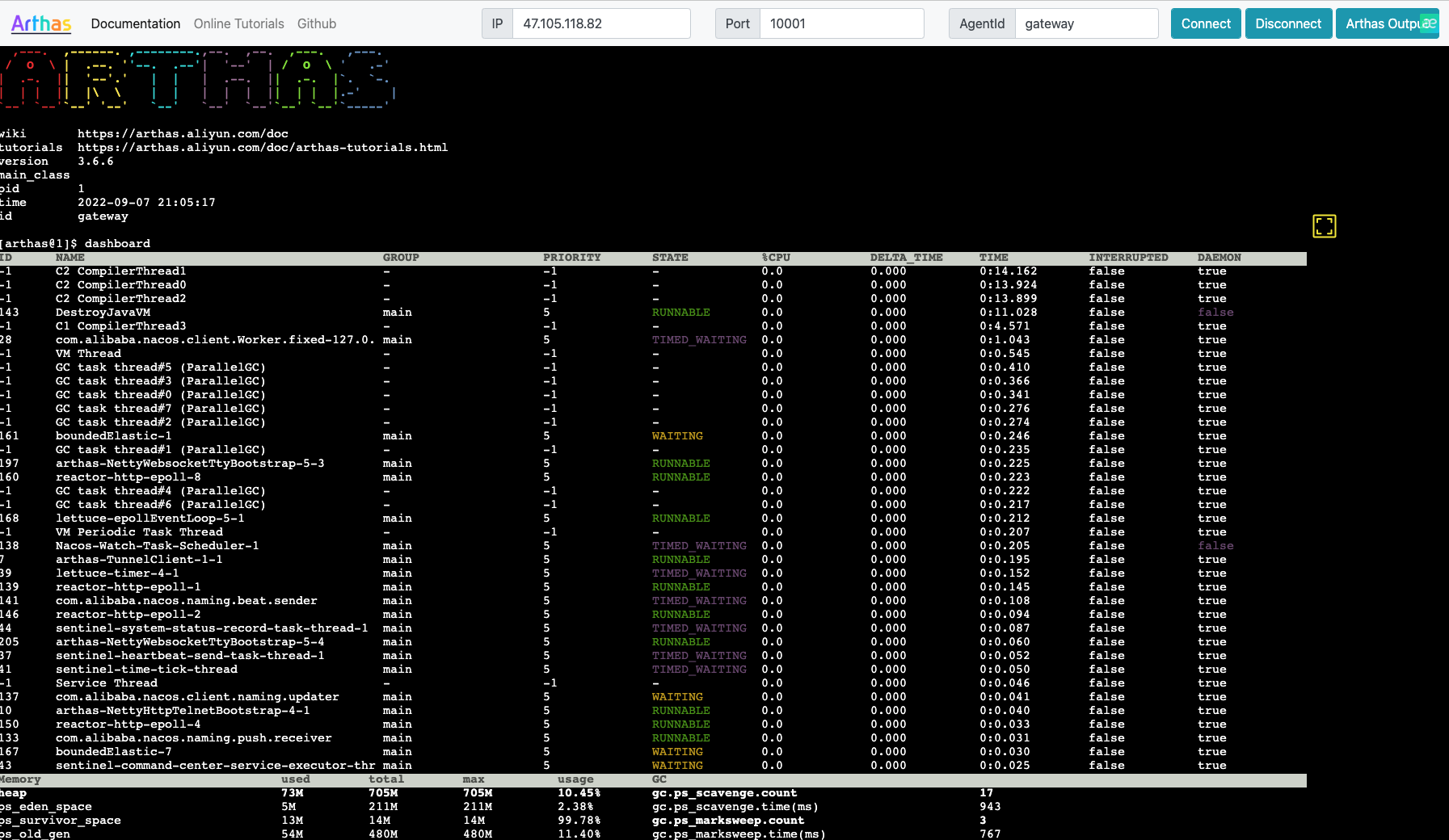
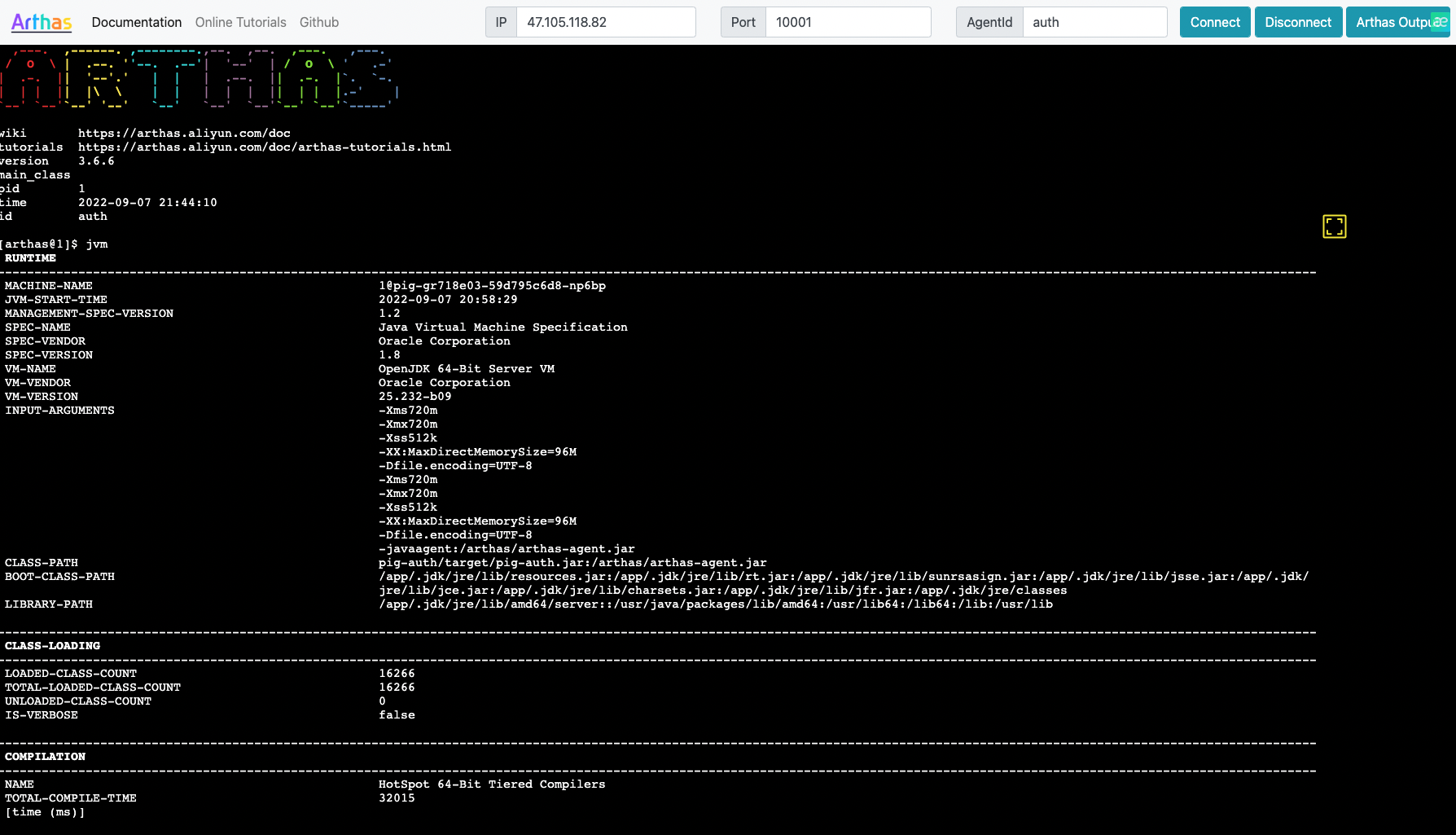
使用 CurveAdm 部署 CurveFS
CurveAdm 是 Curve 团队为提高系统易用性而设计的工具,其主要用于快速部署和运维 CurveBS/CurveFS 集群。主要特性:
- 快速部署 CurveBS/CurveFS 集群
- 容器化服务
- 运维 CurveBS/CurveFS 集群
- 同时管理多个集群
- 一键升级
- 错误精确定位
安装 CurveAdm
bash -c "$(curl -fsSL https://curveadm.nos-eastchina1.126.net/script/install.sh)"
主机列表
主机模块用来统一管理用户主机,以减少用户在各配置文件中重复填写主机 SSH 连接相关配置。我们需导入部署集群和客户端所需的机器列表,以便在之后的各类配置文件中填写部署服务的主机名。
这里采用一台服务器,做单节点集群。
配置免密登陆
生成密钥并配置服务器免密登陆
# 一直回车即可
ssh-keygen
# 使用 ssh-copy-id 配置
ssh-copy-id root@172.31.98.243
# 验证免密
ssh root@172.31.98.243
# 无需输入密码登陆成功即可
导入主机列表
准备主机列表文件 hosts.yaml
$ vim hosts.yaml
global:
user: root # ssh 免密登陆用户名
ssh_port: 22 # ssh 端口
private_key_file: /root/.ssh/id_rsa # 密钥路径
hosts:
- host: curve
hostname: 172.31.98.243
导入主机列表
$ curveadm hosts commit hosts.yaml
查看主机列表
$ curveadm hosts ls
准备集群拓扑文件
CurveFS 支持单机部署和高可用部署,这里我们采用单机部署验证。
创建 topology.yaml 文件,只需修改 target: curve,其他都默认即可。
$ vim topology.yaml
kind: curvefs
global:
report_usage: true
data_dir: ${home}/curvefs/data/${service_role}${service_host_sequence}
log_dir: ${home}/curvefs/logs/${service_role}${service_host_sequence}
container_image: opencurvedocker/curvefs:v2.4
variable:
home: /tmp
target: curve
etcd_services:
config:
listen.ip: ${service_host}
listen.port: 2380${service_host_sequence} # 23800,23801,23802
listen.client_port: 2379${service_host_sequence} # 23790,23791,23792
deploy:
- host: ${target}
- host: ${target}
- host: ${target}
mds_services:
config:
listen.ip: ${service_host}
listen.port: 670${service_host_sequence} # 6700,6701,6702
listen.dummy_port: 770${service_host_sequence} # 7700,7701,7702
deploy:
- host: ${target}
- host: ${target}
- host: ${target}
metaserver_services:
config:
listen.ip: ${service_host}
listen.port: 680${service_host_sequence} # 6800,6801,6802
listen.external_port: 780${service_host_sequence} # 7800,7801,7802
global.enable_external_server: true
metaserver.loglevel: 0
braft.raft_sync: false
deploy:
- host: ${target}
- host: ${target}
- host: ${target}
config:
metaserver.loglevel: 0
部署集群
添加 my-cluster 集群,并指定集群拓扑文件
curveadm cluster add my-cluster -f topology.yaml
切换 my-cluster 集群为当前管理集群
curveadm cluster checkout my-cluster
开始部署集群
$ curveadm deploy
......
Cluster 'my-cluster' successfully deployed ^_^.
终端出现 Cluster 'my-cluster' successfully deployed ^_^. 即部署成功。
查看集群运行情况
$ curveadm status
Get Service Status: [OK]
cluster name : my-cluster
cluster kind : curvefs
cluster mds addr : 192.168.3.81:6700,192.168.3.81:6701,192.168.3.81:6702
cluster mds leader: 192.168.3.81:6702 / 7f5b7443c563
Id Role Host Replicas Container Id Status
-- ---- ---- -------- ------------ ------
6ae9ac1ae448 etcd curve 1/1 d3ecb4e81318 Up 17 minutes
c45e2f0b9266 etcd curve 1/1 8ce9befa54b8 Up 17 minutes
6c6bde442a04 etcd curve 1/1 cbf093c6605f Up 17 minutes
9516d8f5d9ae mds curve 1/1 f338ec63c493 Up 17 minutes
fe2bf5d8a072 mds curve 1/1 b423c3351256 Up 17 minutes
7f5b7443c563 mds curve 1/1 7ad99cee6b61 Up 17 minutes
e6fe68d23220 metaserver curve 1/1 d4a8662d4ed2 Up 17 minutes
b2b4dbabd7bf metaserver curve 1/1 65d7475e0bc4 Up 17 minutes
426ac76e28f9 metaserver curve 1/1 f413efeeb5c9 Up 17 minutes
部署 Rainbond
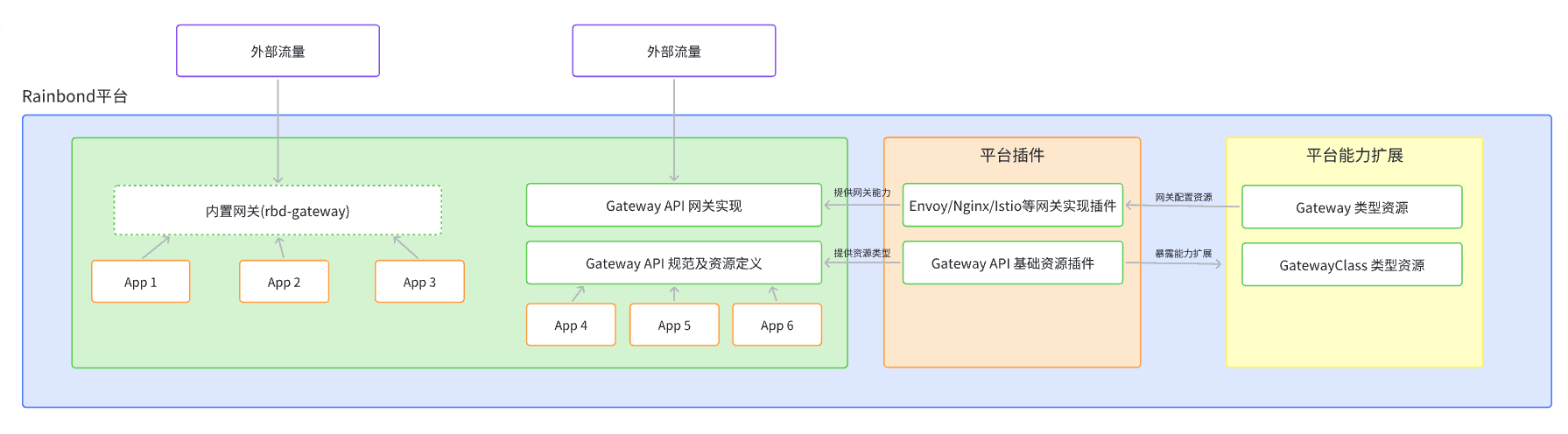
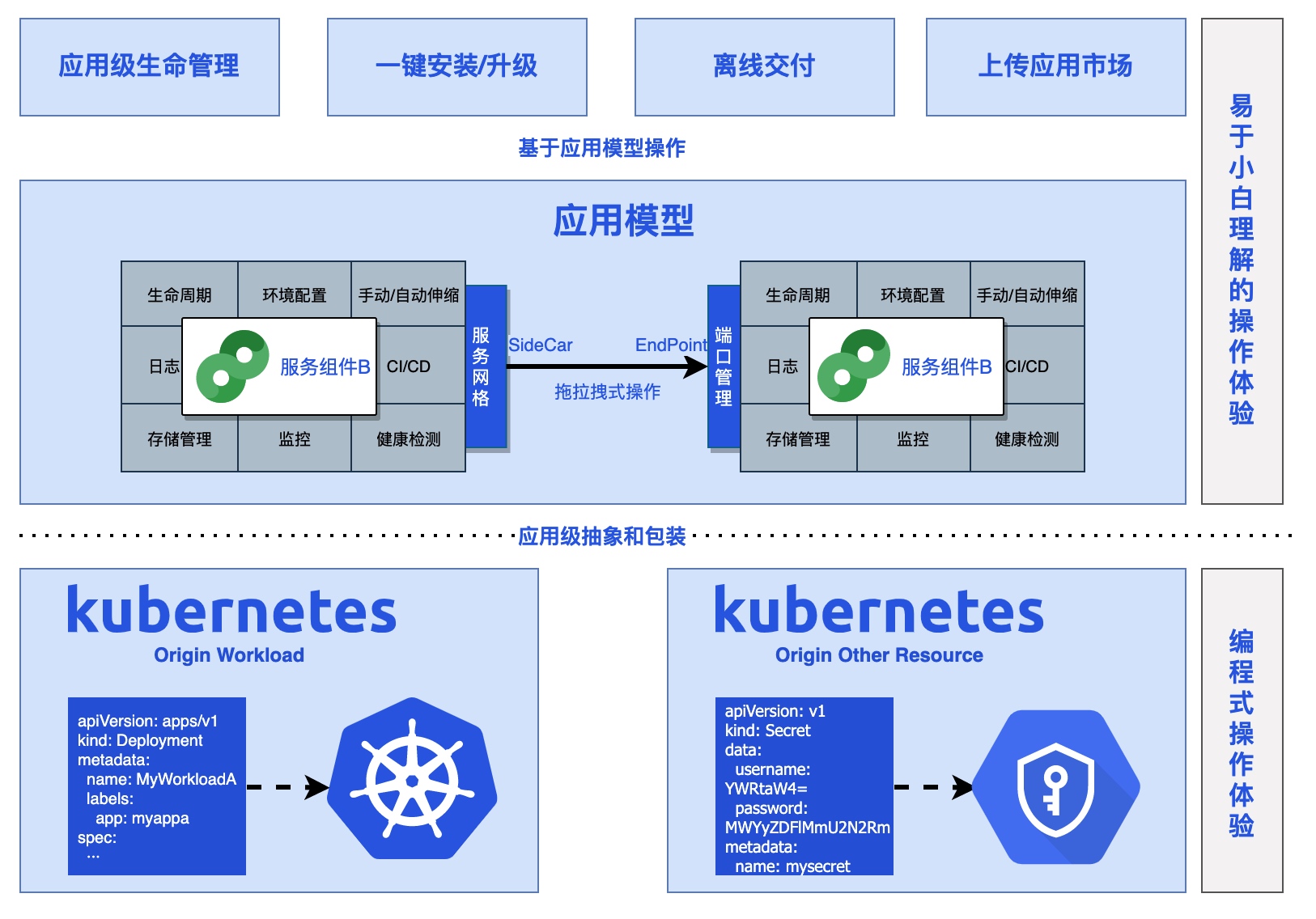
Rainbond 是一个云原生应用管理平台,使用简单,不需要懂容器、Kubernetes和底层复杂技术,支持管理多个Kubernetes集群,和管理企业应用全生命周期。
可以通过一条命令快速安装 Rainbond 单机版。
curl -o install.sh https://get.rainbond.com && bash ./install.sh
执行完上述脚本后,耐心等待 3-5 分钟,可以看到如下日志输出,表示 Rainbond 已启动完成。
INFO: Rainbond started successfully, Please pass http://$EIP:7070 Access Rainbond
部署 MinIO
由于目前 CurveFS 只支持 S3 作为后端存储,CurveBS 后端即将支持。 所以我们需要部署一个 MinIO 对象存储。
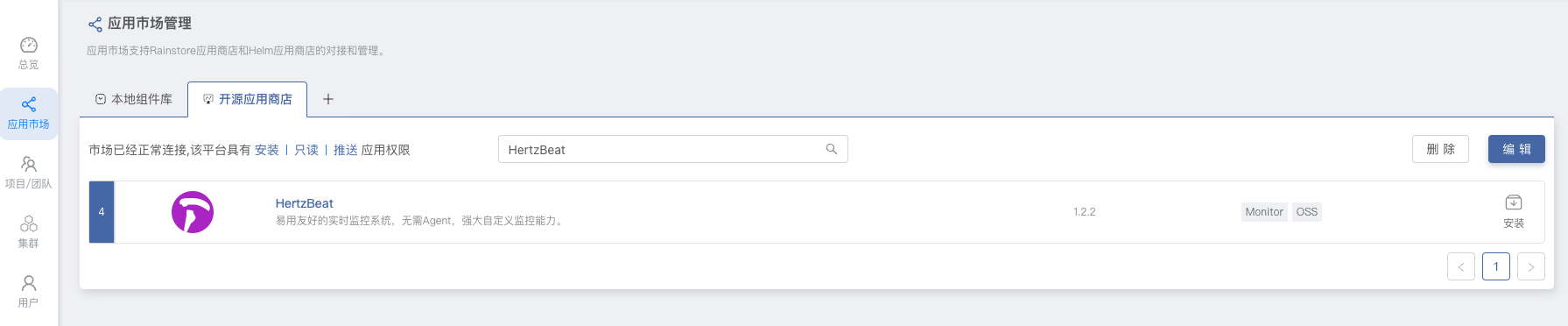
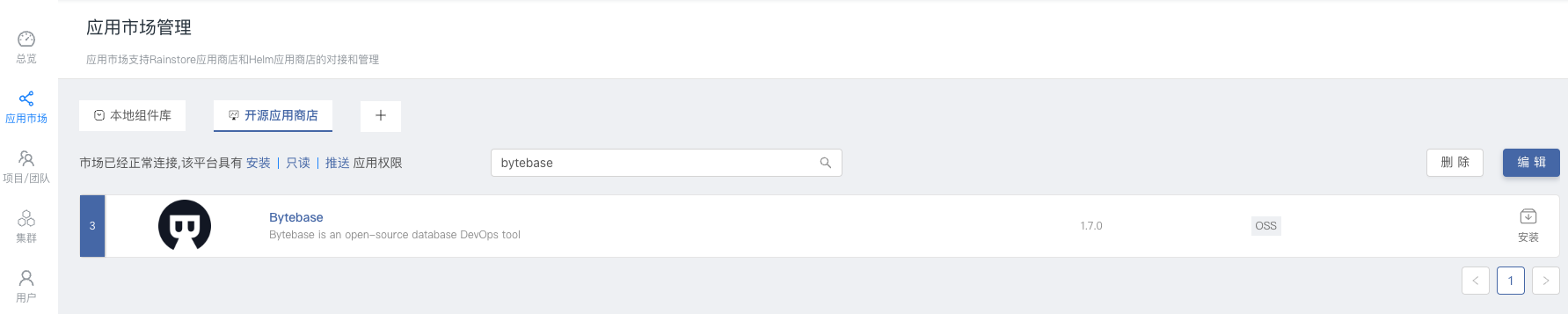
通过 Rainbond 开源应用商店一键部署单机版 MinIO 或者集群版 MinIO。进入到 Rainbond 的 平台管理 -> 应用市场,在开源应用商店中搜索 minio 进行一键安装。
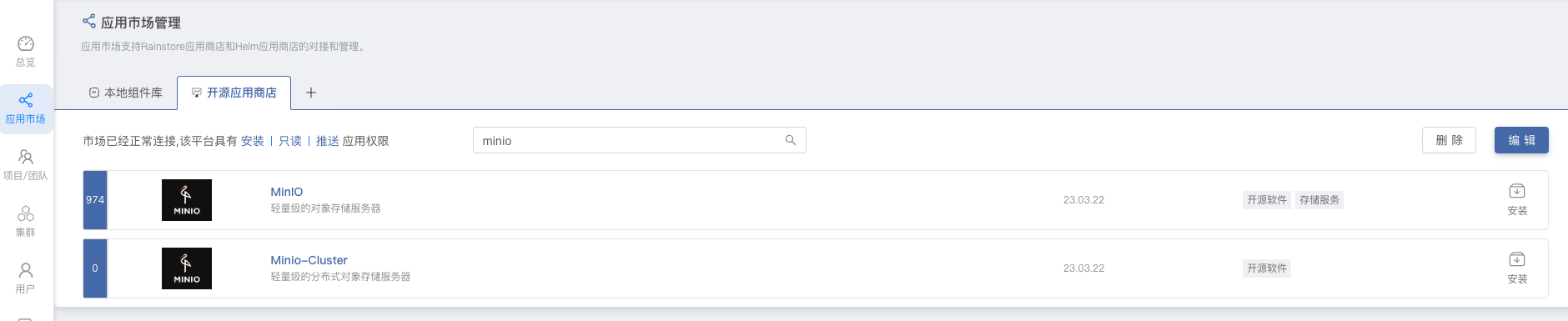
部署完成后,通过 Rainbond 提供的域名访问 MinIO 控制台,默认用户密码 minio/minio123456。然后需要创建一个 Bucket 供 CurveFS 使用。
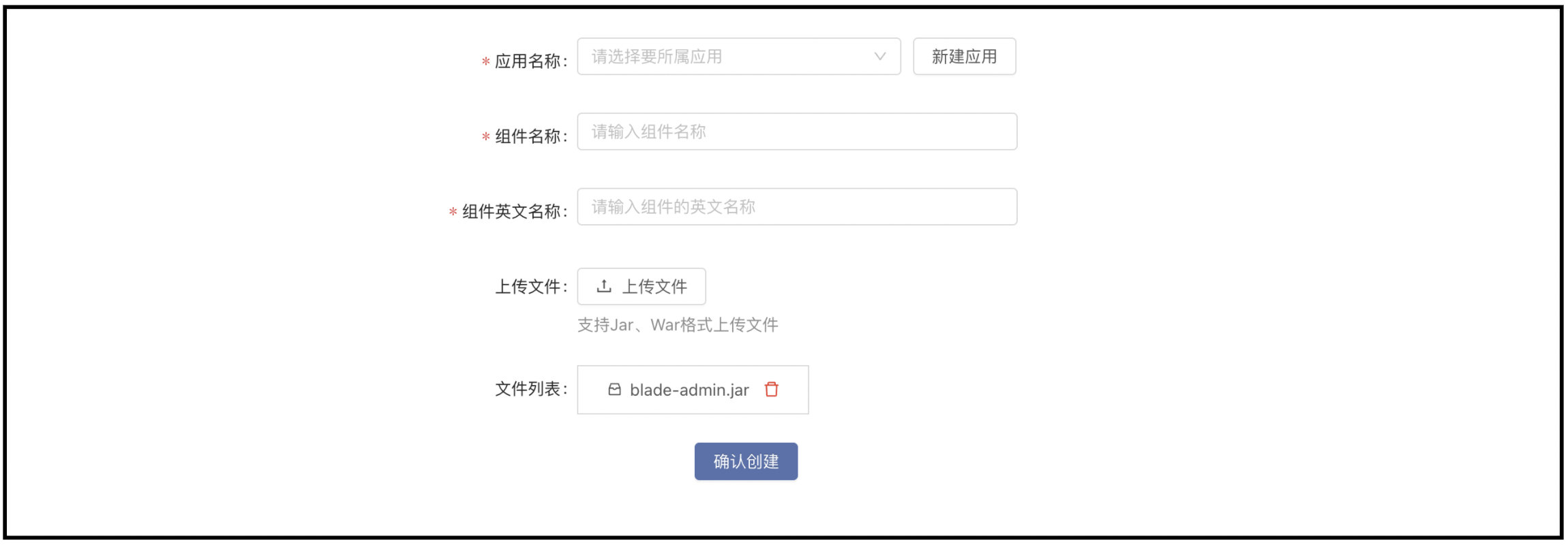
部署 CurveFS-CSI
- 前提:Rainbond 版本要在 v5.13+
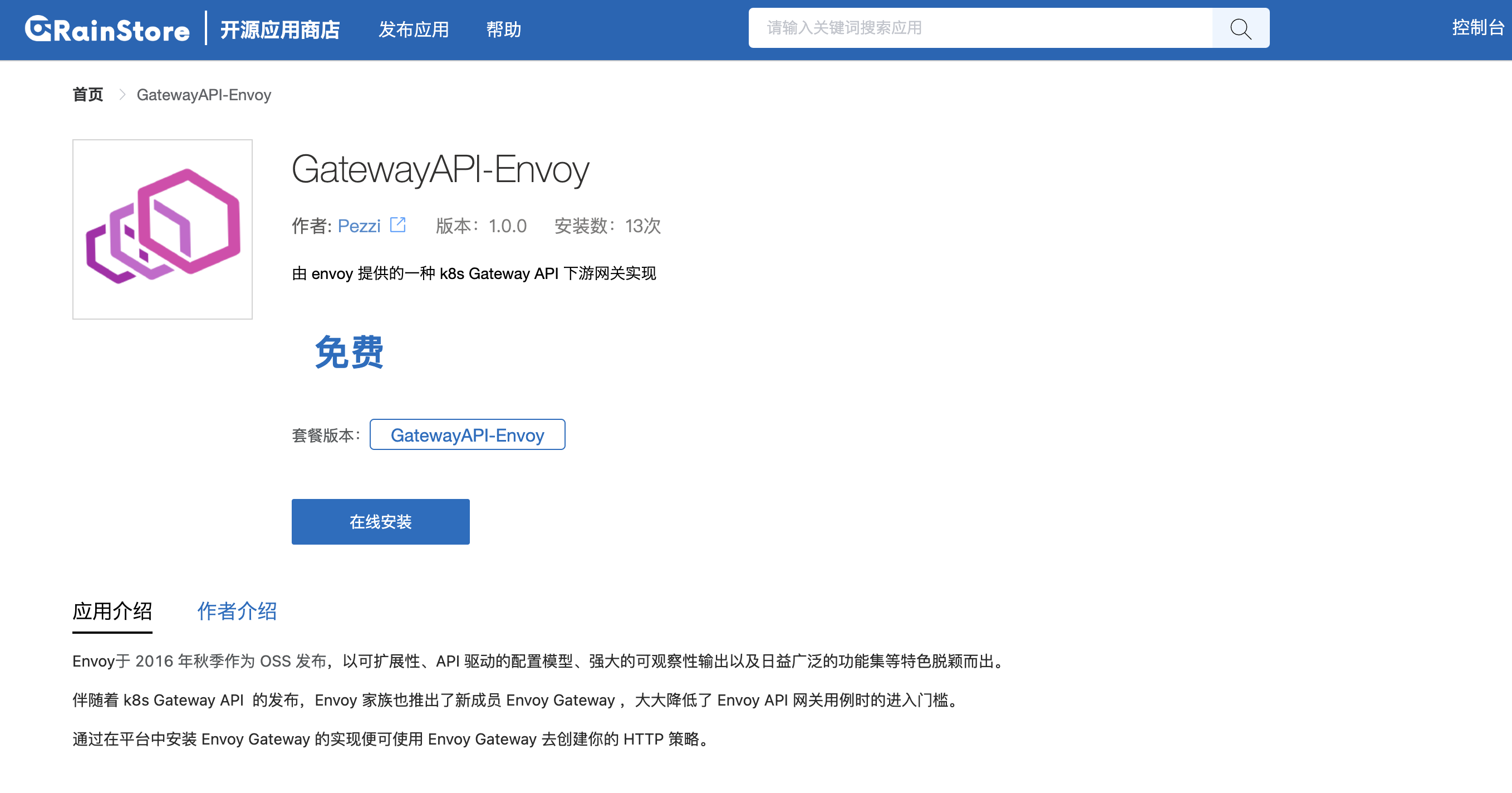
通过 Rainbond 开源应用商店一键部署,进入到 Rainbond 的 平台管理 -> 应用市场,在开源应用商店中搜索 curve-csi 进行一键安装。

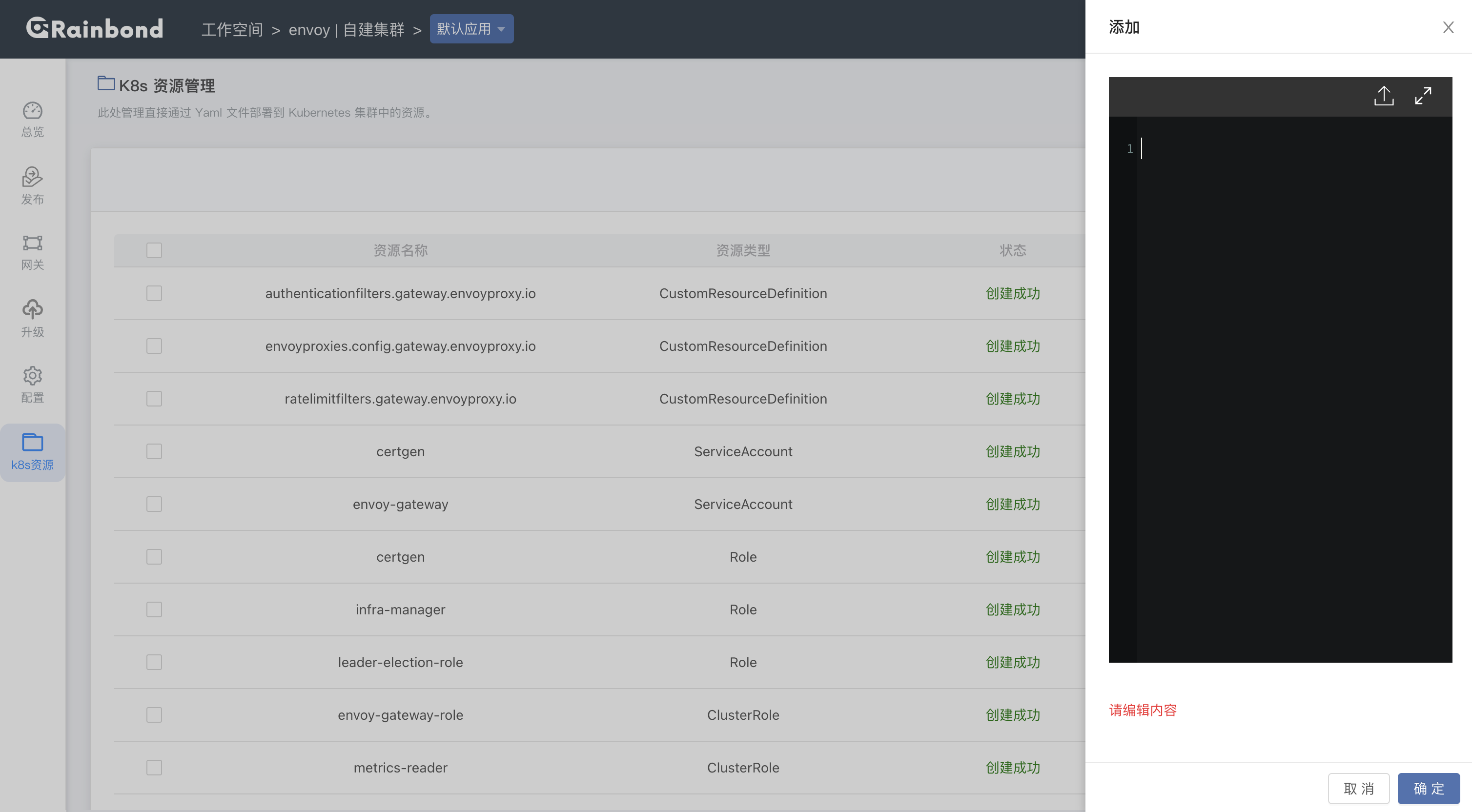
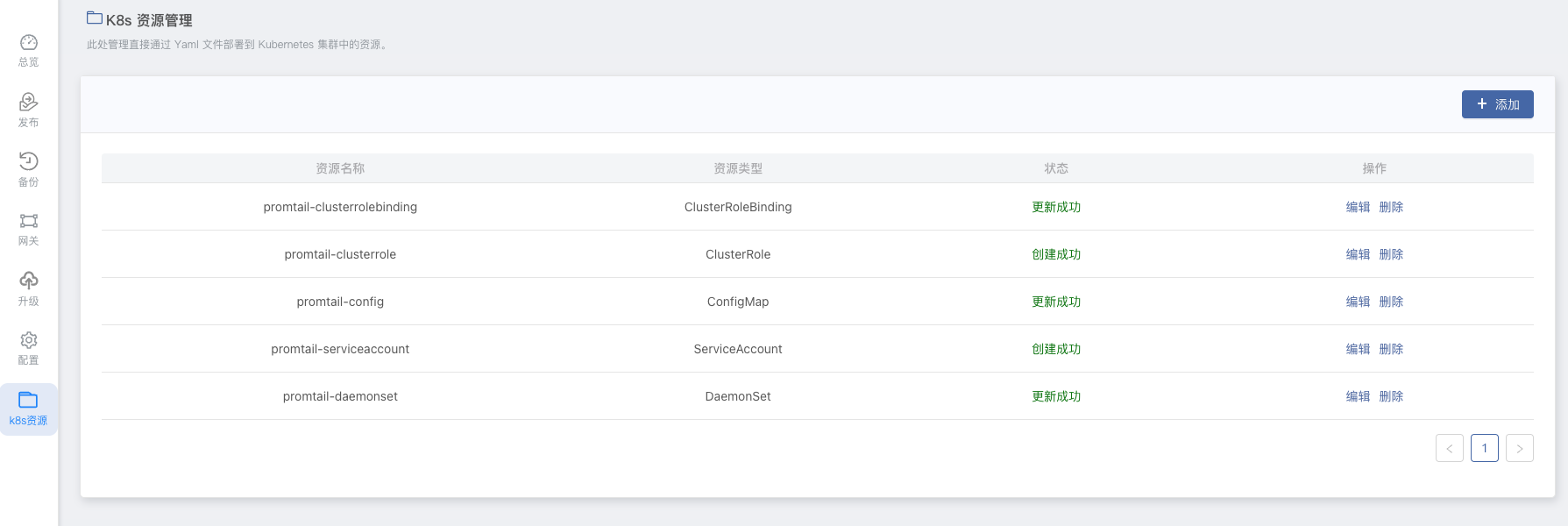
由于 CurveFS-CSI 没有 Rainbond 应用模型类的组件,都属于 k8s 资源类型,可在 应用视图内 -> k8s资源 下看到。
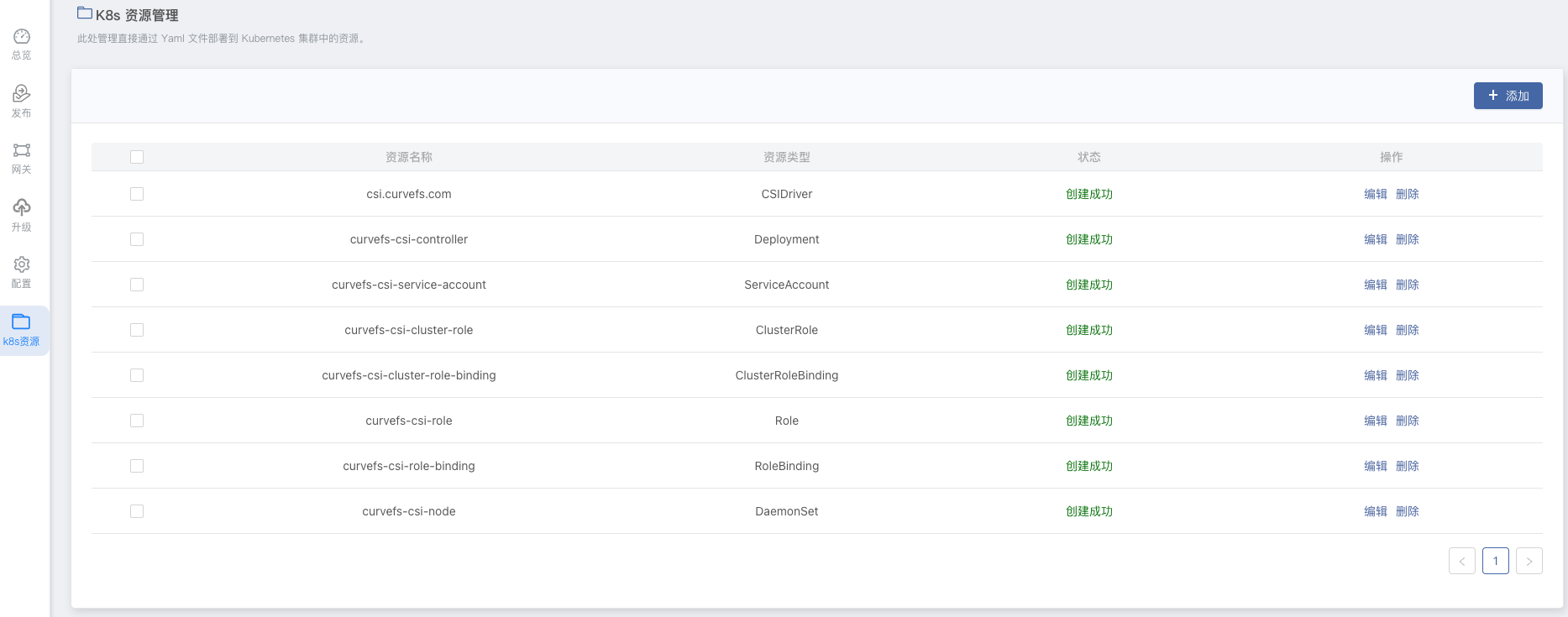
安装完成后,需要修改 curvefs-csi-cluster-role-binding 和 curvefs-csi-role-binding 的 namespace 为当前团队的 namespace,如当前团队 namespace 为 dev,如下:
# curvefs-csi-role-binding
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: curvefs-csi-role-binding
......
subjects:
- kind: ServiceAccount
name: curvefs-csi-service-account
namespace: dev # changed
# curvefs-csi-cluster-role-binding
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: curvefs-csi-cluster-role-binding
......
subjects:
- kind: ServiceAccount
name: curvefs-csi-service-account
namespace: dev # changed
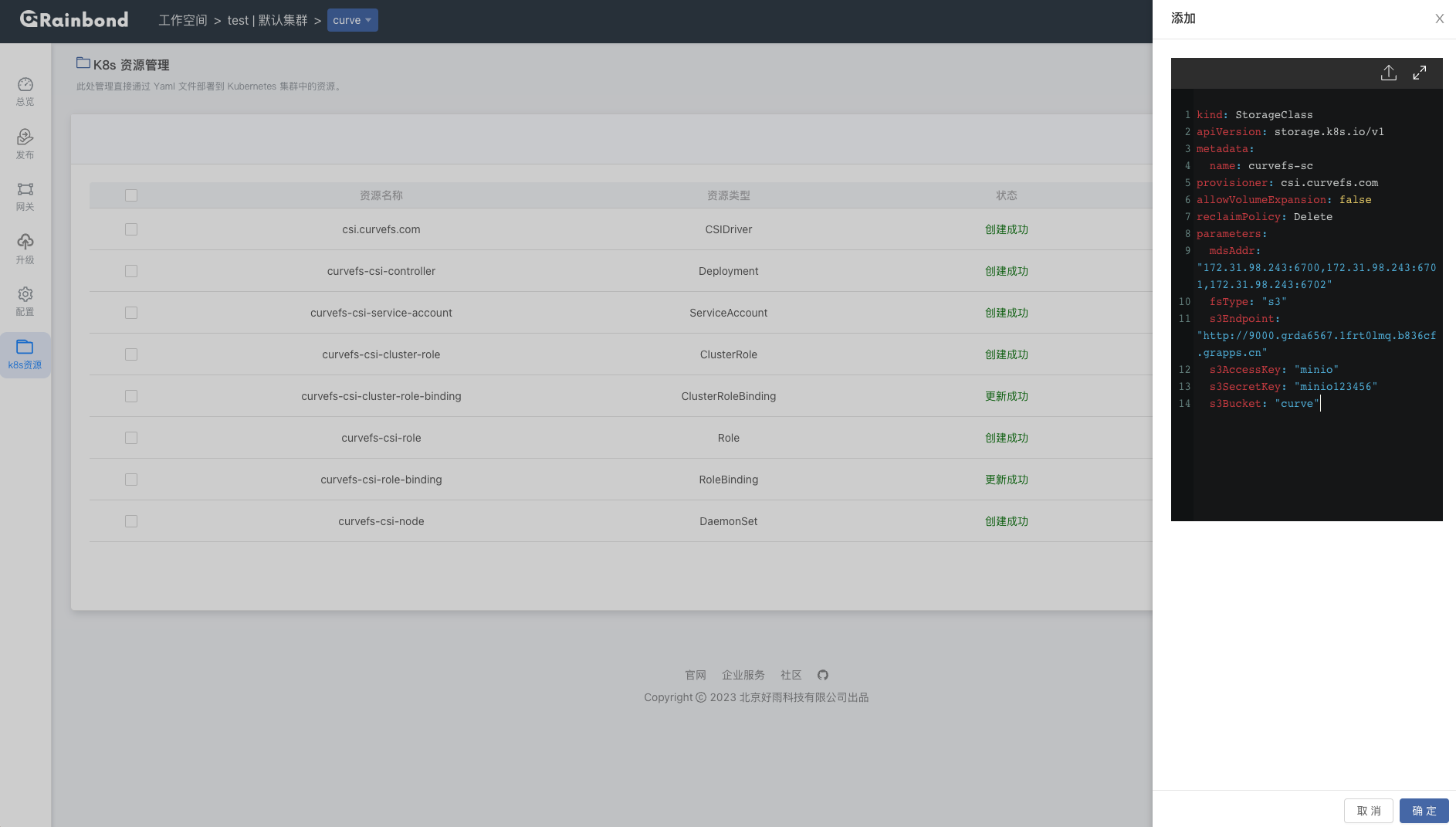
创建 storageclass 资源,同样在 应用视图内 -> k8s资源 -> 添加:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: curvefs-sc
provisioner: csi.curvefs.com
allowVolumeExpansion: false
reclaimPolicy: Delete
parameters:
mdsAddr: "172.31.98.243:6700,172.31.98.243:6701,172.31.98.243:6702"
fsType: "s3"
s3Endpoint: "http://9000.grda6567.1frt0lmq.b836cf.grapps.cn"
s3AccessKey: "minio"
s3SecretKey: "minio123456"
s3Bucket: "curve"
mdsAddr:通过
curveadm status命令获取。$ curveadm status
......
cluster mds addr : 172.31.98.243:6700,172.31.98.243:6701,172.31.98.243:6702s3Endpoint:填写 MinIO 组件的 9000 端口对外服务域名。
s3AccessKey:MinIO 访问 Key,填 root 用户或生成 AccessKey。
s3SecretKey:MinIO 密钥 Key,填 root 密码或生成 SecretKey。
s3Bucket:MinIO 桶名称。
在 Rainbond 上使用 CurveFS
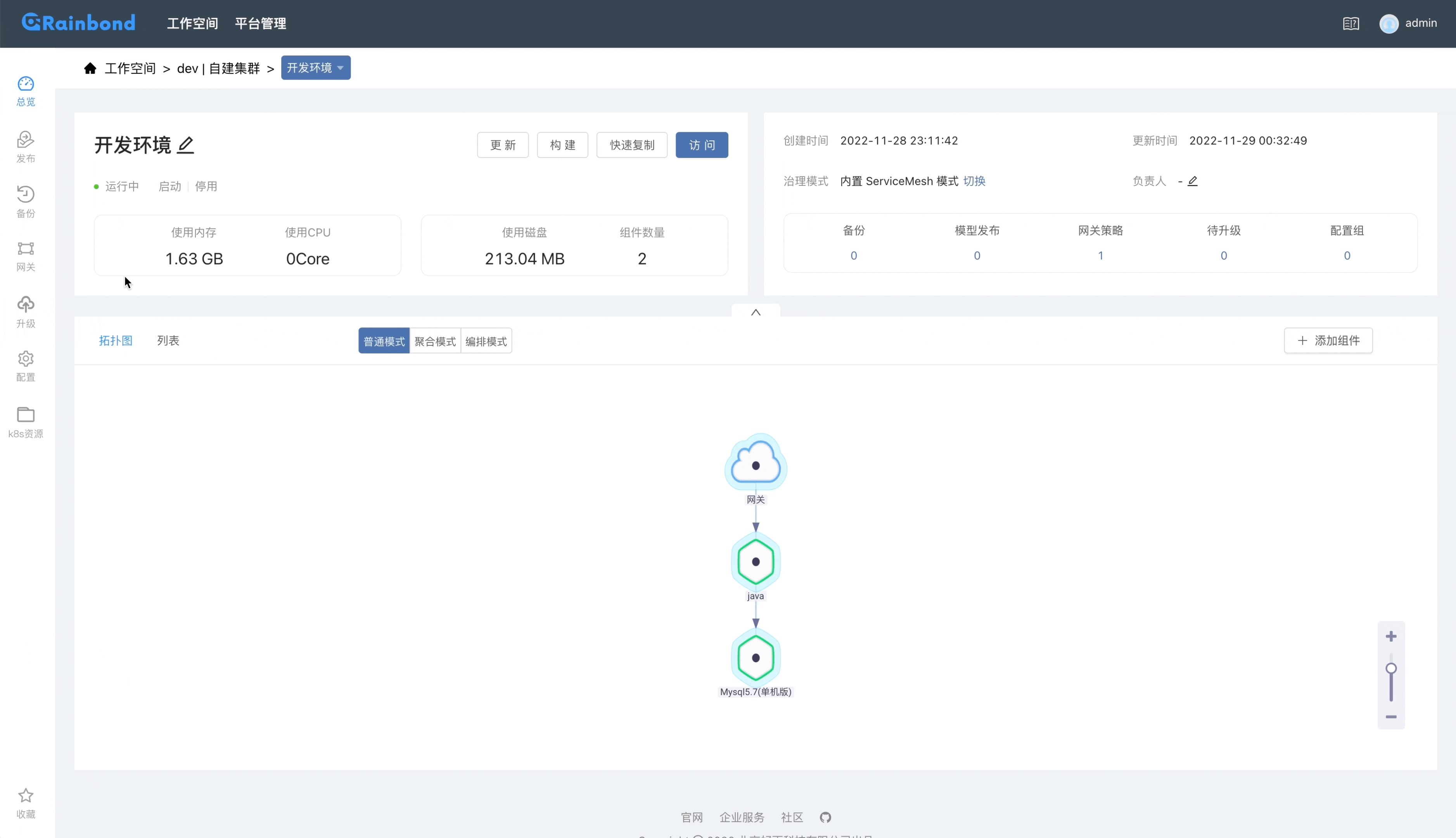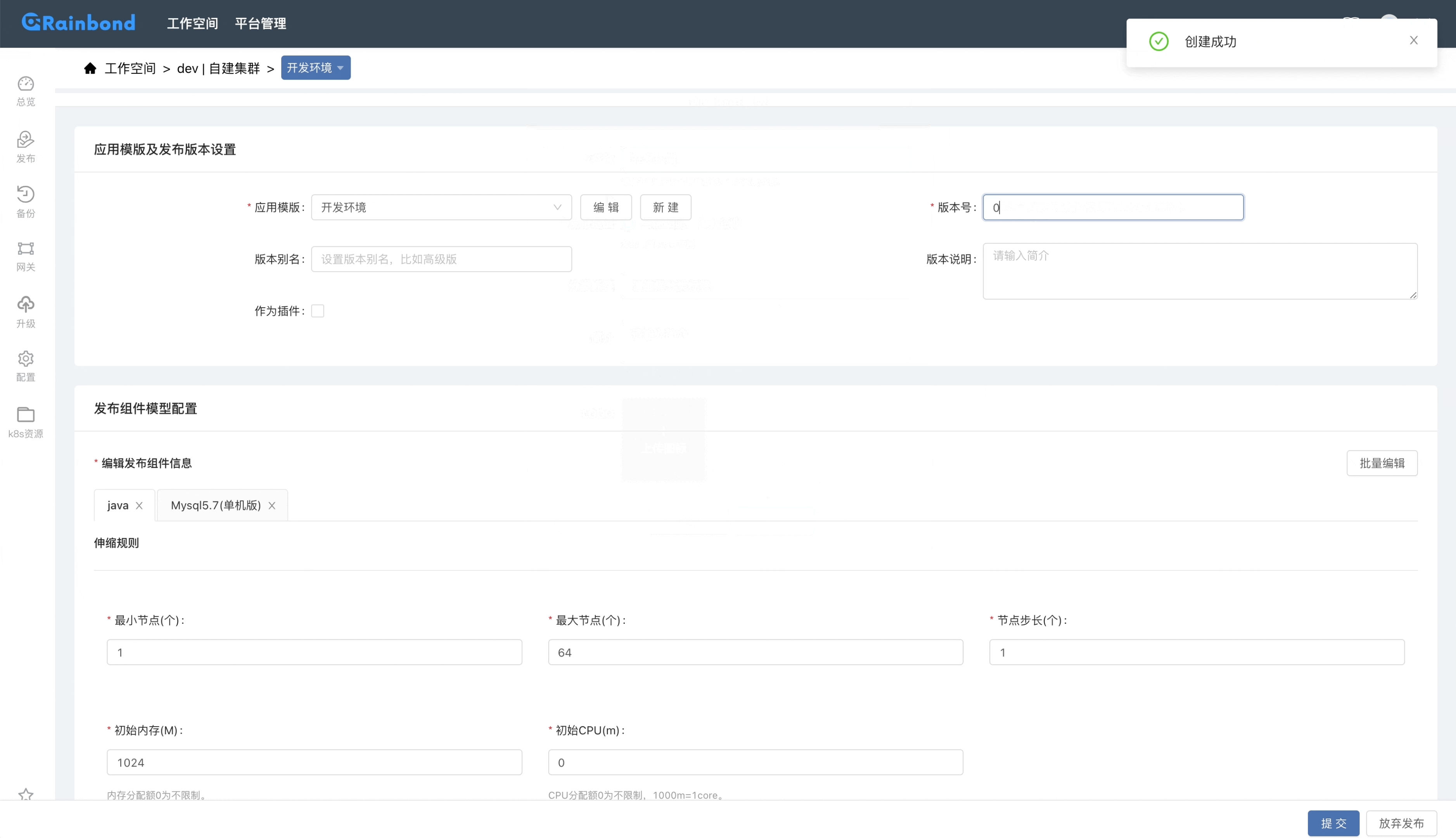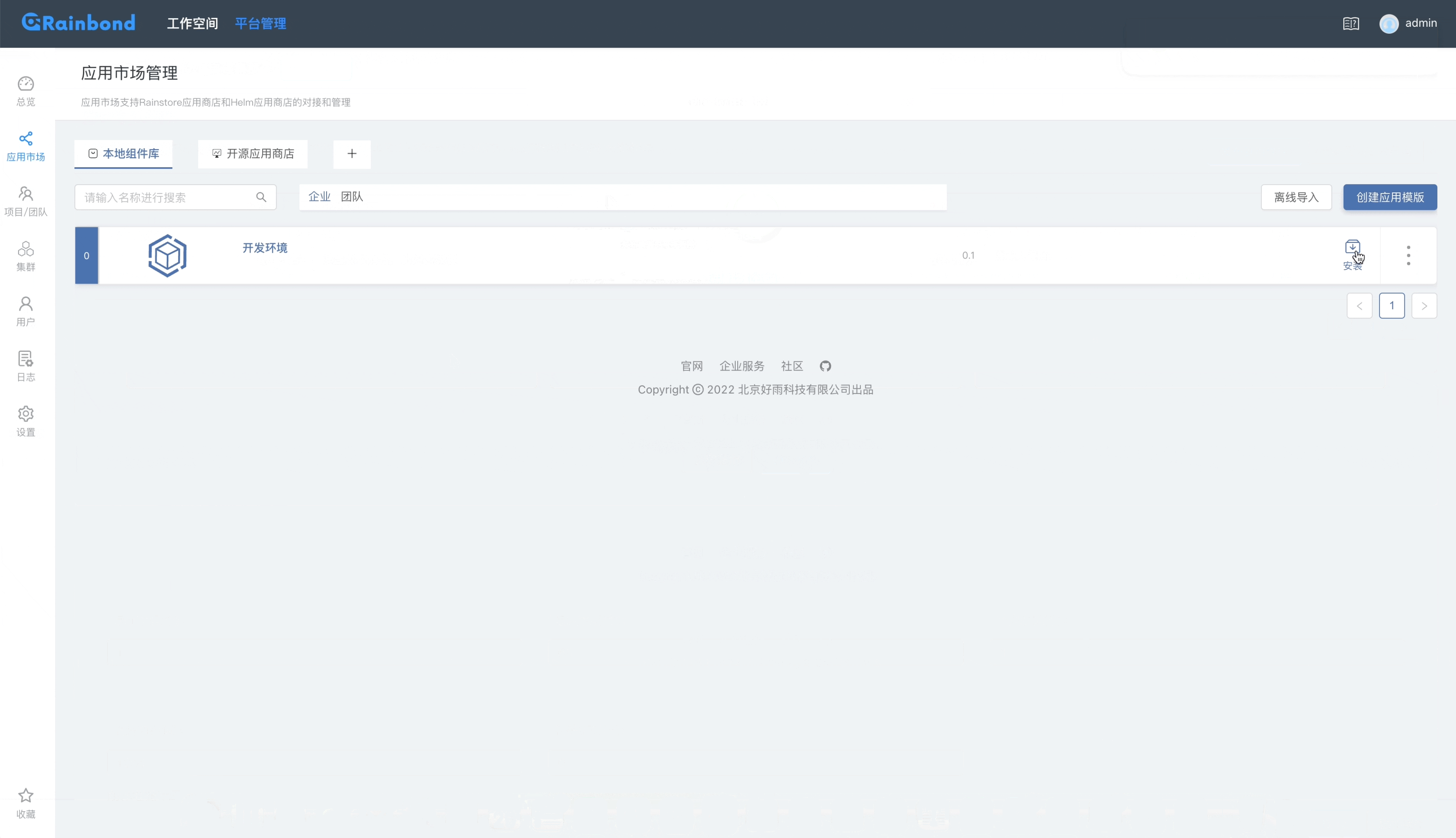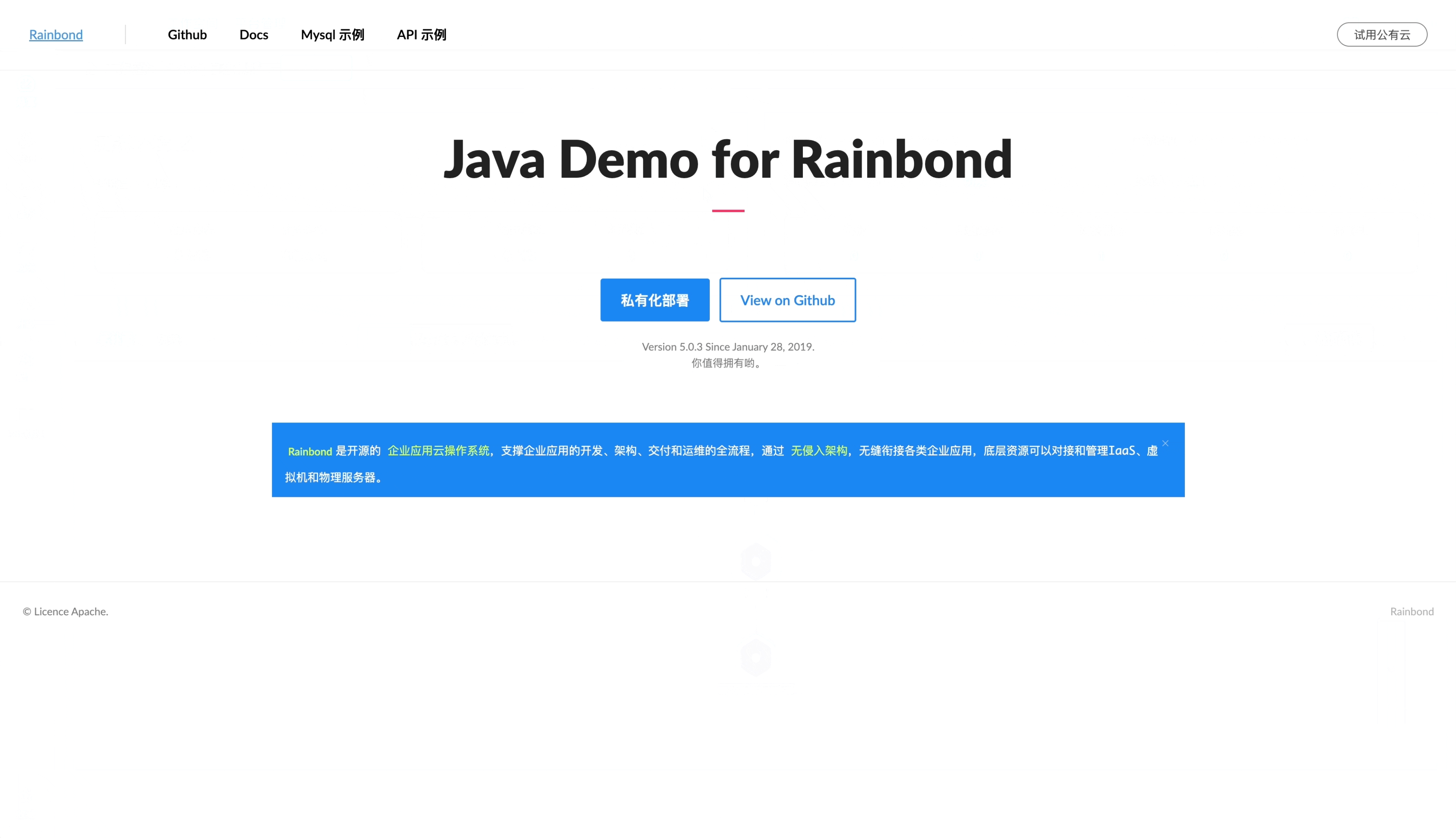
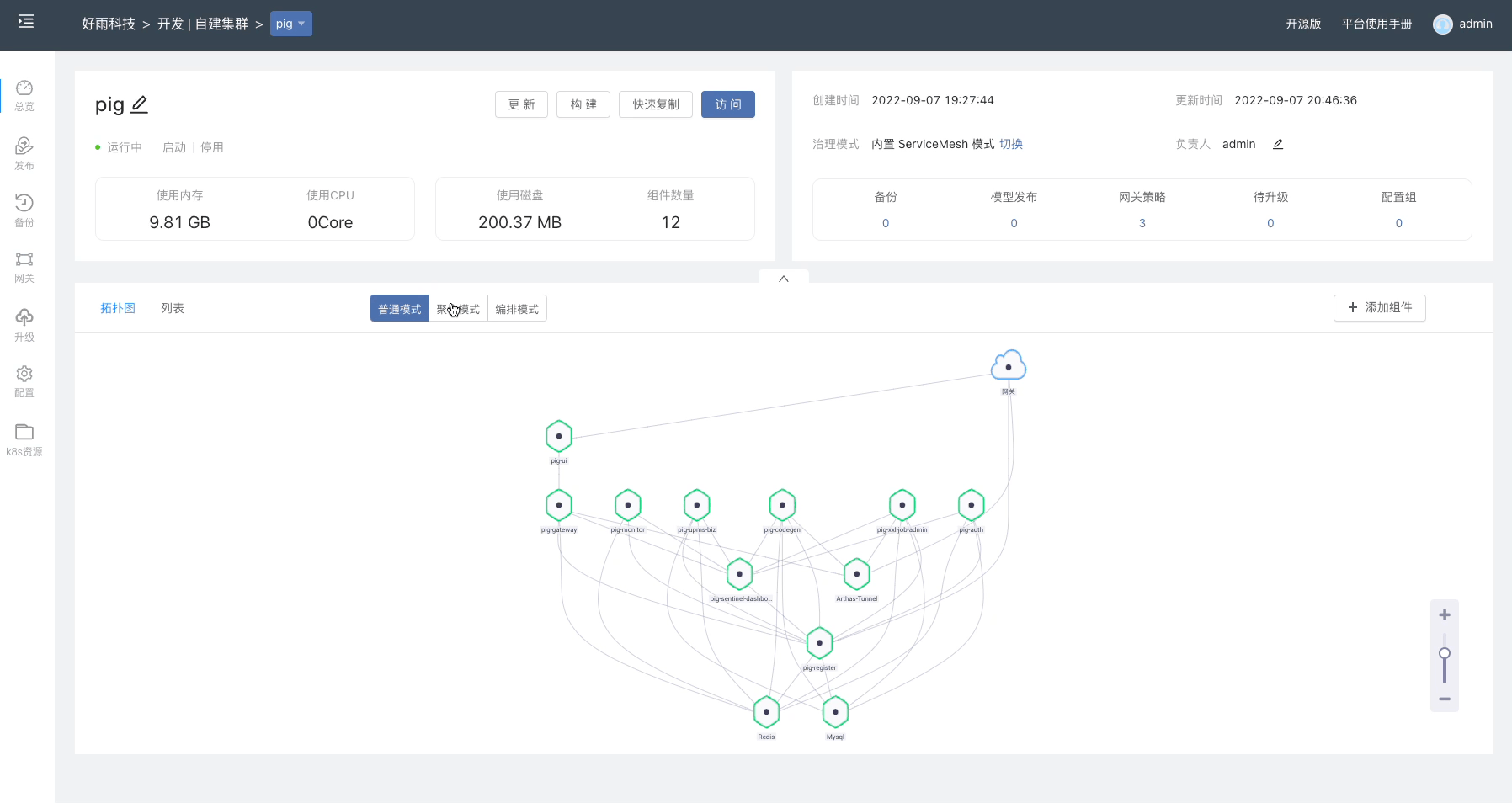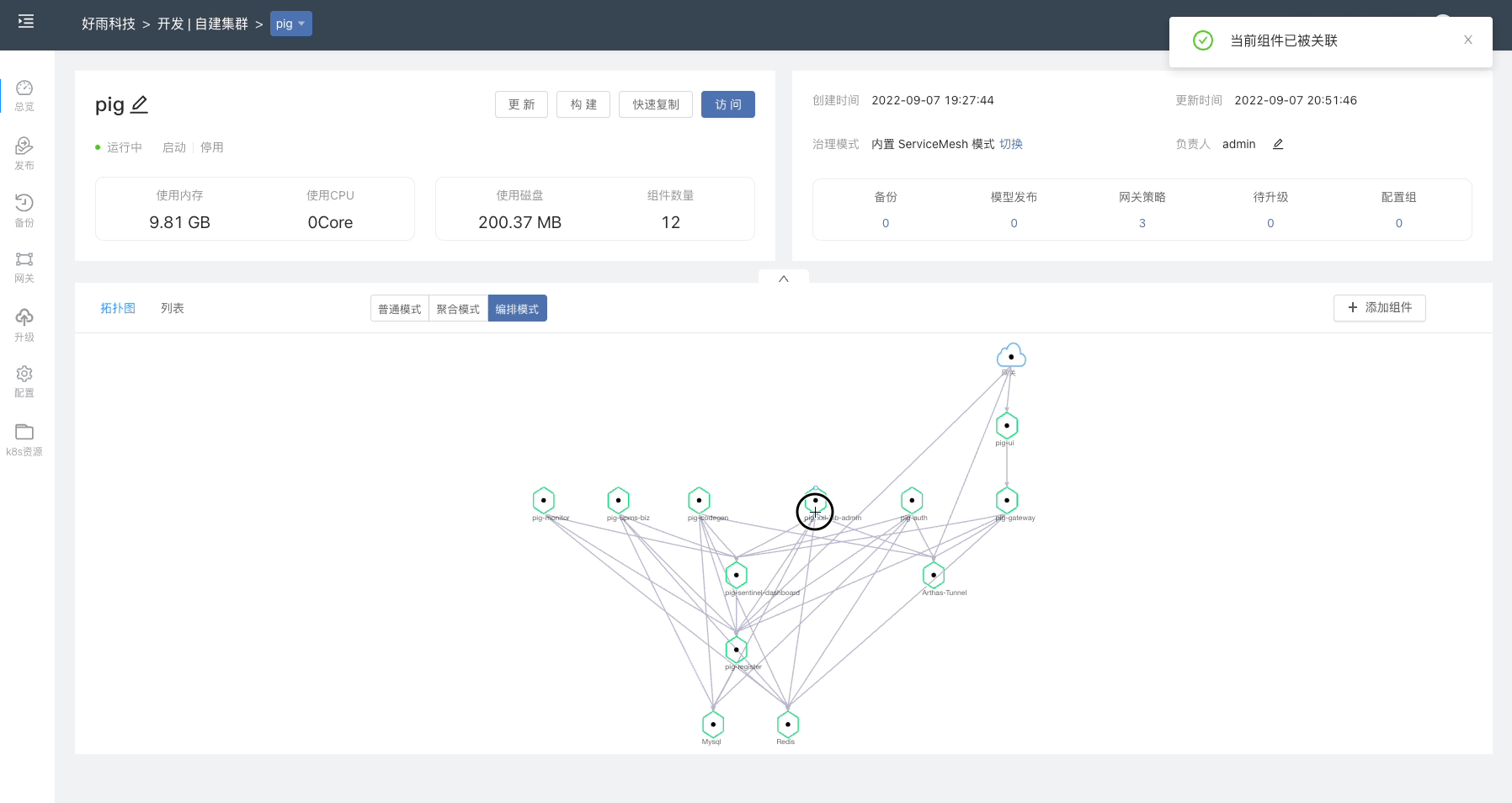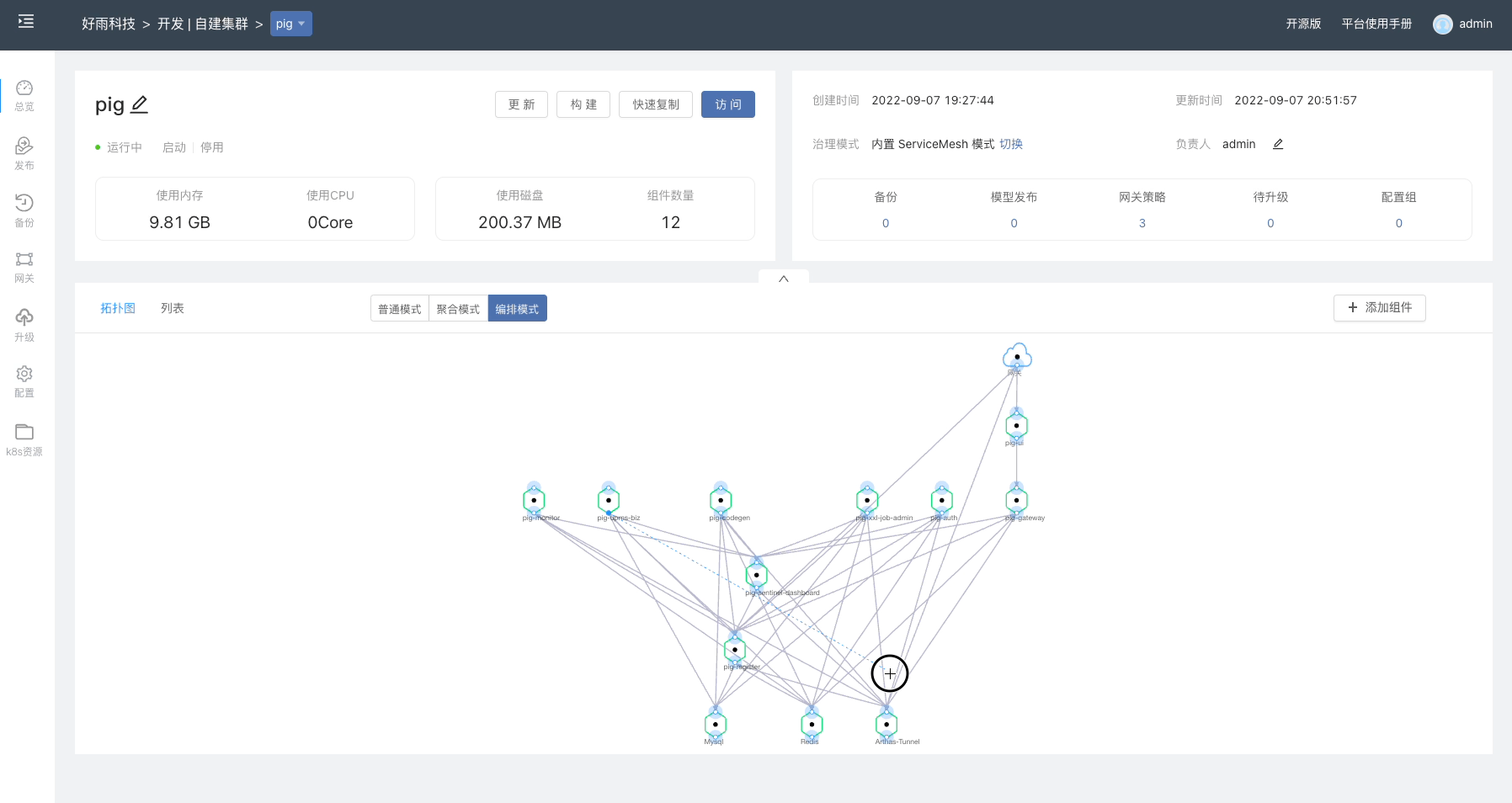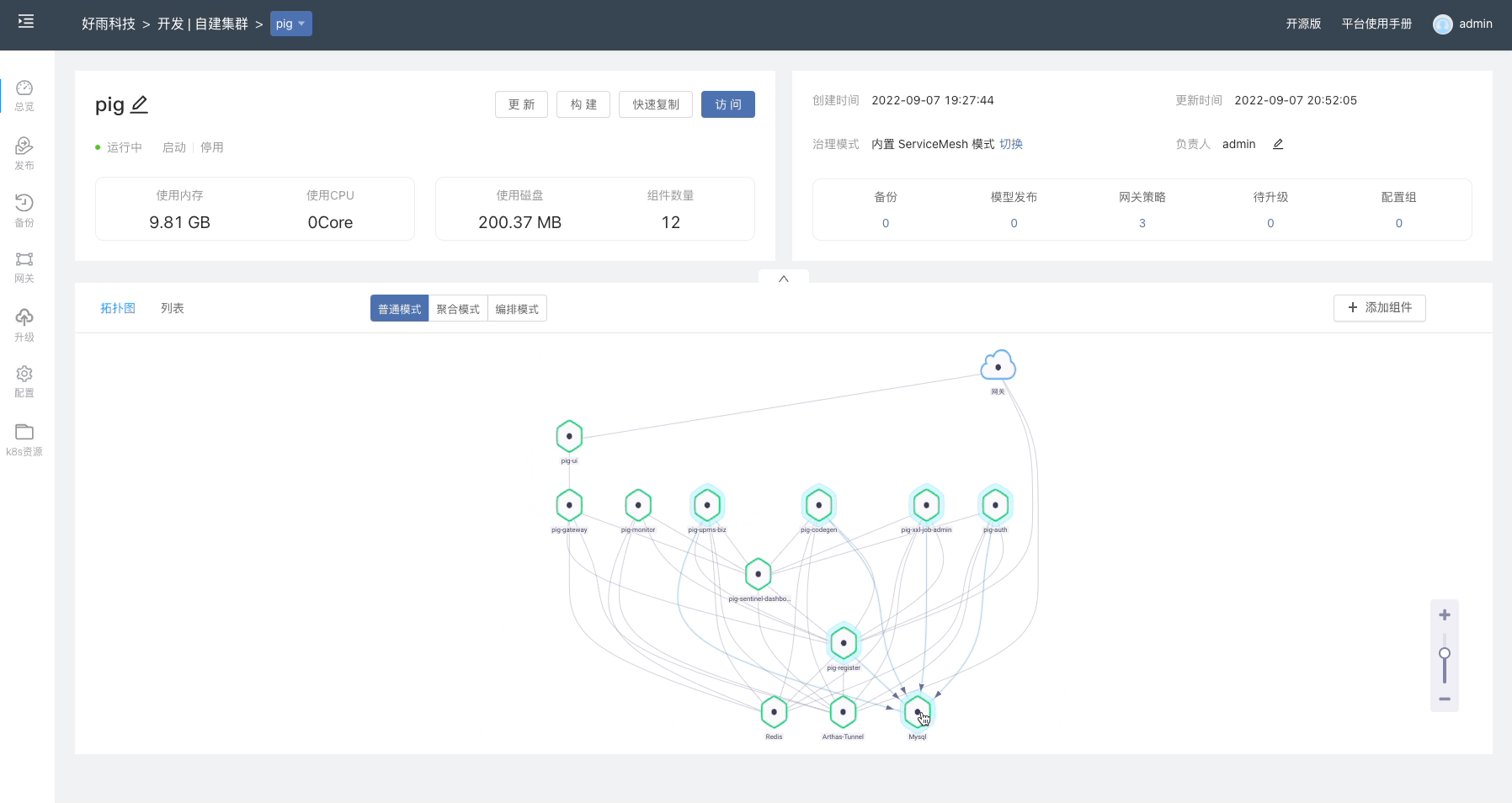
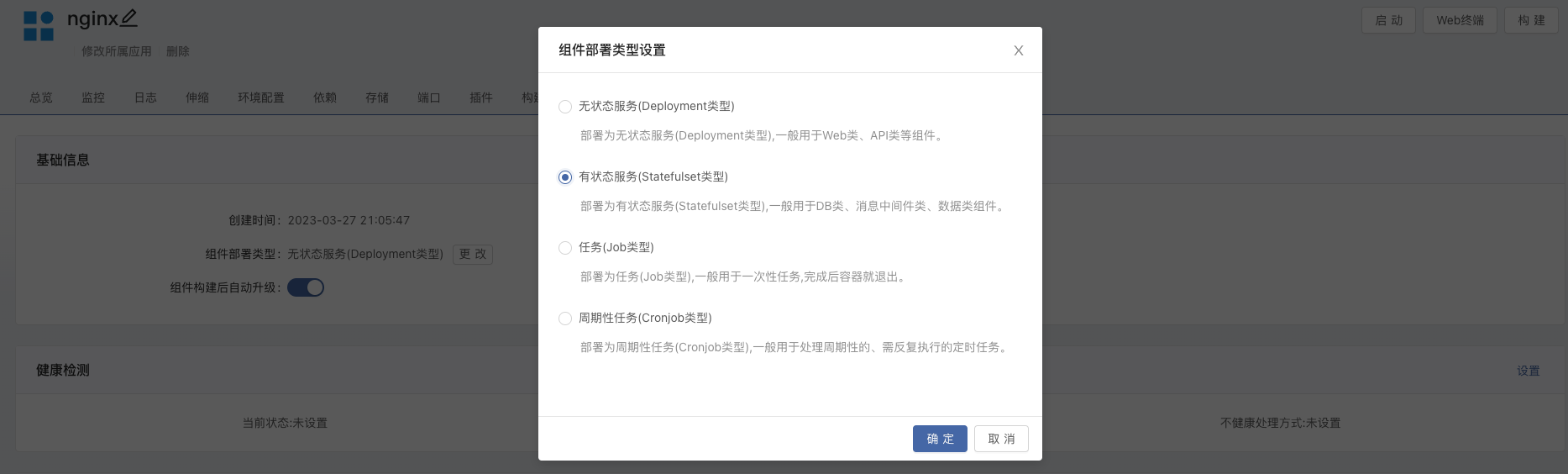
通过镜像创建一个 Nginx 组件,在 组件 -> 其他设置 修改组件部署类型为 有状态服务。在 Rainbond 上只有 有状态服务 可以使用自定义存储,无状态服务使用默认的共享存储。
进入到 组件 -> 存储 添加存储,选择类型为 curvefs-sc,保存并重启组件。
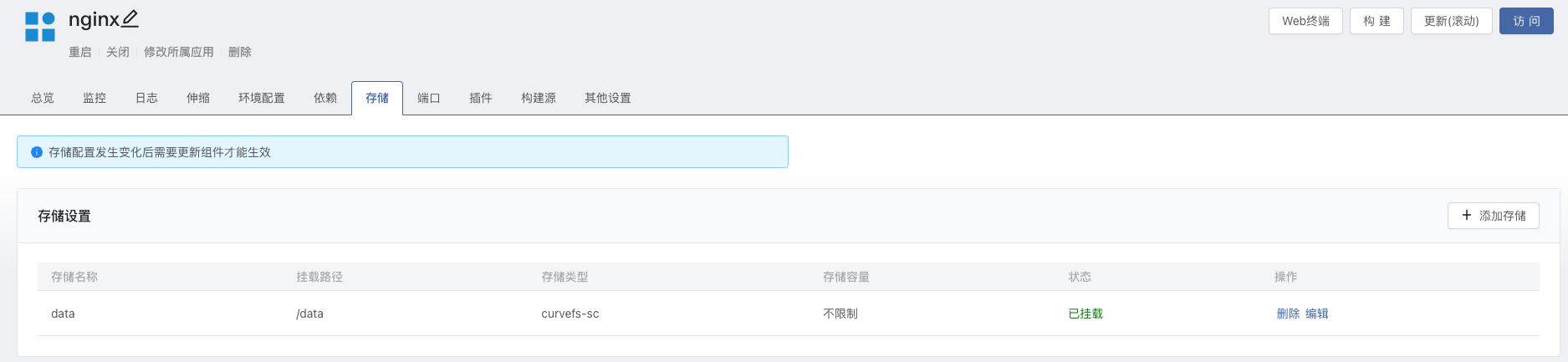
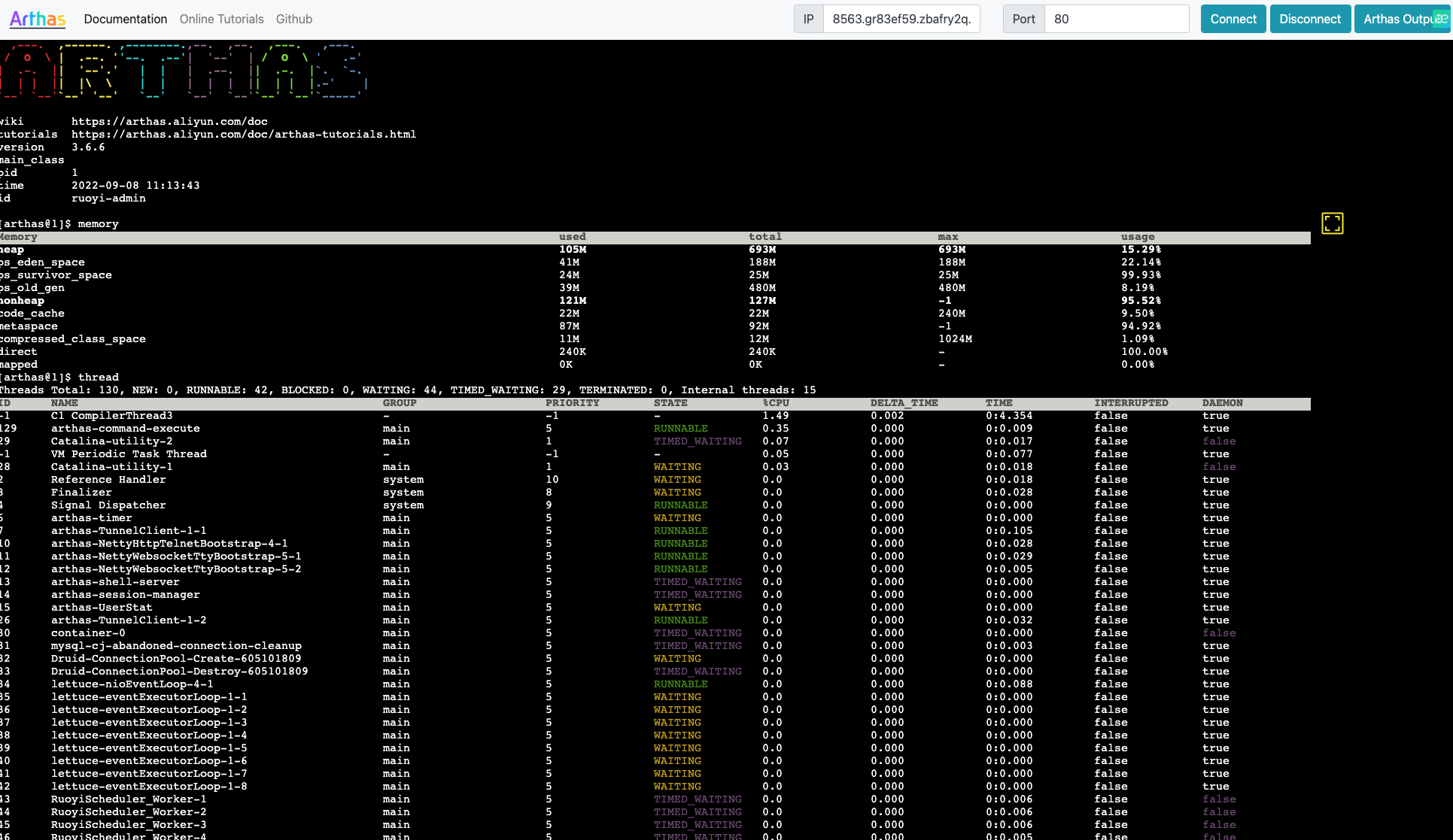
等待组件启动完成后,进入组件的 Web 终端内,测试写入数据。
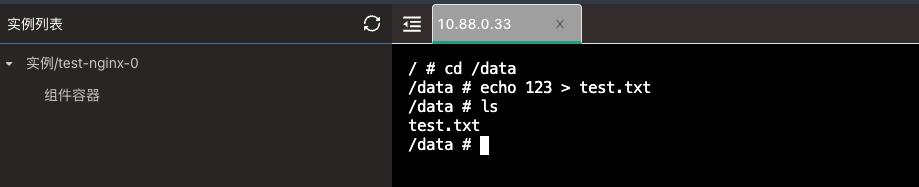
然后进入到 MinIO 桶内查看,数据已写入。

未来规划
Rainbond 社区未来会使用 Curve 云原生存储作为 Rainbond 底层的共享存储,为用户提供更好、更简单的云原生应用管理平台和云原生存储,共同推进开源社区生态以及给用户提供一体化的解决方案。